
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 리눅스
- 월간결산
- 텐서플로
- 파이썬 시각화
- 한빛미디어
- Pandas
- 한빛미디어서평단
- python visualization
- 통계학
- 시각화
- matplotlib
- SQL
- MySQL
- 서평
- Visualization
- Linux
- Google Analytics
- 블로그
- 딥러닝
- Ga
- 매틀랩
- 티스토리
- tensorflow
- Python
- 독후감
- 파이썬
- 서평단
- Blog
- Tistory
- MATLAB
- Today
- Total
목록분류 전체보기 (596)
pbj0812의 코딩 일기
 [PYTHON] matplotlib 으로 Parallel Categories Charts 구현하기
[PYTHON] matplotlib 으로 Parallel Categories Charts 구현하기
0. 목표 - matplotlib 으로 Parallel Categories Charts 구현하기 1. plotly 의 Parallel Categories Charts 1) library 호출 import plotly.express as px import pandas as pd 2) 데이터 생성 iris = px.data.iris() 3) 그림 그리기 fig = px.parallel_coordinates(iris, color="species_id") fig.show() - 결과 2. matplotlib 으로 구현 1) library 호출 import matplotlib.pyplot as plt import pandas as pd # ytick 강제 변형을 위해 사용 import numpy as np imp..
 [PYTHON] GridSpec 을 이용한 여러 그래프를 같이 그리기
[PYTHON] GridSpec 을 이용한 여러 그래프를 같이 그리기
0. 목표 - GridSpec 을 이용한 여러 그래프를 같이 그리기 1. 실습 1) library 호출 import seaborn as sns import matplotlib.pyplot as plt from matplotlib import gridspec 2) 데이터 생성 flights_long = sns.load_dataset("flights") 3) heatmap 용 데이터 flights = flights_long.pivot("month", "year", "passengers") 4) barplot 용 데이터 year_df = flights_long.groupby(by = 'year').agg({'passengers' : 'sum'}) month_df = flights_long.groupby(by ..
 [PYTHON] 태극문양 그리기
[PYTHON] 태극문양 그리기
0. 목표 - 태극문양 그리기 1. 실습 1) library 호출 import matplotlib.pyplot as plt import math import numpy as np 2) 반원 데이터 생성 - 붉은 반원, 푸른 반원으로 쪼개서 그리기 # 붉은 반원 x1 = np.linspace(-math.sqrt(2.5 * 2.5 * 9 / 13), 2.5, 1000) y1 = [] for i in x1: y1.append(math.sqrt((2.5 * 2.5) - (i * i))) x2 = np.linspace(math.sqrt(2.5 * 2.5 * 9 / 13), 2.5, 1000) y2 = [] for i in x2: y2.append(-math.sqrt((2.5 * 2.5) - (i * i))) x_..
 [PYTHON] matplotlib 으로 전단지 만들기
[PYTHON] matplotlib 으로 전단지 만들기
0. 목표 - matplotlib 으로 전단지 만들기 1. 실습 1) library 호출 import matplotlib.pyplot as plt # 한글폰트 from matplotlib import rc rc('font', family='AppleGothic') plt.rcParams['axes.unicode_minus'] = False # text 꾸미기 import matplotlib.transforms as mtransforms import matplotlib.patches as mpatch from matplotlib.patches import FancyBboxPatch # image import matplotlib.image as mpimg from matplotlib.offsetbox imp..
 [PYTHON] indicate_inset_zoom 을 이용한 줌 인
[PYTHON] indicate_inset_zoom 을 이용한 줌 인
0. 목표 - indicate_inset_zoom 을 이용한 줌 인 1. 실습 1) library 호출 import matplotlib.pyplot as plt import numpy as np 2) 데이터 생성 - 줌인할 데이터(5 * 5) small = np.array([ [1.0, 0.5, 1.0, 0.1, 0.3], [0.5, 0.5, 0.5, 0.2, 0.4], [1.0, 0.5, 1.0, 0.3, 0.6], [0.5, 0.5, 0.5, 0.2, 0.4], [1.0, 0.5, 1.0, 0.1, 0.3] ]) - 0으로 이루어진 전체 데이터(200 * 200) - 50, 70 지점에 small 데이터를 얹는 형태 big = np.zeros((200, 200)) ny, nx = small.shape..
 [PYTHON] table 을 사용하여 그래프와 테이블을 같이 그리기
[PYTHON] table 을 사용하여 그래프와 테이블을 같이 그리기
0. 목표 - table 을 사용하여 그래프와 테이블을 같이 그리기 1. 실습 1) library 호출 import pandas as pd import numpy as np import matplotlib.pyplot as plt 2) 데이터 생성 df = pd.DataFrame( {'A' : [1, 2, 3, 4, 5], 'B' : [10, 20, 30, 40, 50], 'C' : [13, 14, 65, 43, 13]}, index = ['a', 'b', 'c', 'd', 'e'] ) 3) 변수 설정 cell_text = df.values colors = plt.cm.BuPu(np.linspace(0, 0.5, len(df.index))) columns = list(df.columns) rows = l..
 [PYTHON] floweaver 를 이용한 sankey 그래프 그리기
[PYTHON] floweaver 를 이용한 sankey 그래프 그리기
0. 목표 - floweaver 를 이용한 sankey 그래프 그리기 1. 실습 1) library 설치 - chrome 에서 실습할 것, safari 에서는 위젯 표출 시 에러 발생 !pip install ipysankeywidget !pip install floweaver 2) 데이터 생성 - source : 어디에서 - target : 어디로 - type : 무엇을 - value : 얼마만큼 보내는가 flows = pd.DataFrame({ 'source' : ['A', 'B', 'A', 'B', 'A', 'C', 'B', 'D', 'A', 'A'], 'target' : ['a1', 'a1', 'a2', 'a1', 'a3', 'a5', 'a4', 'a2', 'a3', 'a3'], 'type' : [..
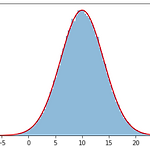 [통계학] 정규분포 그래프 그리기
[통계학] 정규분포 그래프 그리기
0. 목표 - 정규분포 그래프 그리기 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import math 2) 데이터 생성 - 평균 10, 표준편차 4, 데이터의 개수 10 만 개 data = np.random.normal(10, 4, 100000) 3) 정렬 data = sorted(data) 4) 평균 - 9.991368120797462 data_mean = sum(data) / len(data) 5) 표준편차, 분산 - 표준편차 4.013488145962863, 분산 16.10808709778442 sd = 0 for i in data: sd += (i - data_mean) ** 2 sd = math.sqrt(sd /..
 [독후감] 쉽게 배우는 통계학
[독후감] 쉽게 배우는 통계학
0. 도서 정보 - 도서명 : 쉽게 배우는 통계학 - 저자 : 구로세 나오코 - 링크 1. 후기 - 줄거리 : 길고양이가 냥이 선배(집고양이) 에게 통계학을 배우는 내용. - 진행방식 : 만화 + 줄 글 - 장점 : 만화로 되어 있어 보기가 편하다. 난이도가 입문자에게 적절하다. 고양이가 있다. 부록으로 고양이, 조사에 대한 지식을 얻을 수 있다. - 단점 : 통계학에 대한 내용보다 고양이 이야기가 더 많다.
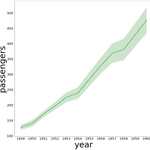 [PYTHON] fill_between 을 이용한 신뢰구간을 포함한 lineplot 구현하기
[PYTHON] fill_between 을 이용한 신뢰구간을 포함한 lineplot 구현하기
0. 목표 - fill_between 을 이용한 신뢰구간을 포함한 lineplot 구현하기 1. seaborn 의 lineplot import seaborn as sns flights = sns.load_dataset("flights") sns.lineplot(data=flights, x="year", y="passengers") 2. 구현하기 0) library 호출 import seaborn as sns import matplotlib.pyplot as plt import math 1) 데이터 확인 flights.head() 2) 변수 생성 - flights_mean : 연도별 탑승자 평균 - flights_year : 연도 - flights_len : 연도별 데이터 길이 flights_mean = ..