
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 텐서플로
- 리눅스
- Python
- python visualization
- 통계학
- 매틀랩
- tensorflow
- 시각화
- 서평
- SQL
- 파이썬 시각화
- 딥러닝
- Linux
- Tistory
- 서평단
- 월간결산
- matplotlib
- 한빛미디어서평단
- Blog
- 한빛미디어
- MySQL
- 티스토리
- 블로그
- 파이썬
- MATLAB
- Ga
- 독후감
- Pandas
- Visualization
- Google Analytics
- Today
- Total
목록분류 전체보기 (596)
pbj0812의 코딩 일기
 [PYTHON] streamlit 으로 대시보드 만들기
[PYTHON] streamlit 으로 대시보드 만들기
0. 목표 - streamlit 으로 대시보드 만들기 1. 설치 및 데모 실행 1) library 설치 pip install streamlit 2) 데모 실행 streamlit hello # 아래 에러 발생시 아래쪽 업그레이드 진행 필요 # AttributeError: module 'google.protobuf.descriptor' has no attribute '_internal_create_key' # pip install --upgrade protobuf - 결과 - 여러 가지 데모들 2. 내 파일로 만들어보기 - 파일 명 : second_app.py - 그림 코드 설명 : 링크 1) library 호출 import numpy as np import matplotlib.pyplot as plt im..
 [PYTHON] stackplot 으로 Age Of Empires 그래프 그리기
[PYTHON] stackplot 으로 Age Of Empires 그래프 그리기
0. 목표 - stackplot 으로 Age Of Empires 그래프 그리기 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import pandas as pd 2) 데이터 프레임 생성 df = pd.DataFrame({ 'A' : [np.random.randint(1, 10) for i in range(100)], 'B' : [np.random.randint(1, 10) for i in range(100)], 'C' : [np.random.randint(1, 10) for i in range(100)]}) 3) 인덱스를 시간으로 대체 df.index = pd.date_range('1/1/2000', periods=100, ..
 [PYTHON] pandas-bokeh 라이브러리 써보기
[PYTHON] pandas-bokeh 라이브러리 써보기
해당 포스팅은 pandas-bokeh의 README.md(링크) 파일 중 일부를 변형 혹은 차용하여 만든 글로 원본을 보시면 더욱 많고 정확한 정보를 얻으실 수 있습니다. 0. 목표 - pandas-bokeh 라이브러리 써보기 1. 실습(jupyter notebook 에서 실습) 1) 설치 !pip install pandas-bokeh 2) library 호출 import pandas as pd import pandas_bokeh 3) 데이터 프레임 생성 - 0부터 999 까지 생성 df = pd.DataFrame({'A' : [i for i in range(1000)]}) 4) line plot 생성 - html 창이 새롭게 열리며 아래와 같이 그래프를 그려줌 df.plot_bokeh(kind="lin..
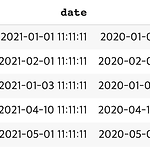 [PYTHON] relativedelta 를 활용한 date_add 구현
[PYTHON] relativedelta 를 활용한 date_add 구현
0. 목표 - relativedelta 를 활용한 date_add 구현 1. 실습하기 1) library 호출 import pandas as pd from dateutil.relativedelta import relativedelta 2) 데이터 프레임 생성 df = pd.DataFrame({'id' : [1, 2, 3, 4, 5], 'date' : ['2021-01-01 11:11:11', '2021-02-01 11:11:11', '2021-01-03 11:11:11', '2021-04-10 11:11:11', '2021-05-01 11:11:11']}) 3) 데이터 형식 변경 df['date'] = pd.to_datetime(df['date'], format="%Y-%m-%d %H:%M:%S") 4)..
 [SQL] MySQL function 생성 및 테스트
[SQL] MySQL function 생성 및 테스트
0. 목표 - MySQL 에서의 function 생성 및 테스트 1. 실습하기(단순 출력) 1) function 생성 - FUNCTION_TEST 실행시 OK 출력 DELIMITER $$ DROP FUNCTION IF EXISTS FUNCTION_TEST$$ CREATE FUNCTION FUNCTION_TEST() RETURNS VARCHAR(20) BEGIN DECLARE Result VARCHAR(10); SET Result = 'OK'; RETURN Result; END $$ DELIMITER ; 2) 에러 확인 및 수정 Error Code: 1418. This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declarat..
 [SQL] 서브쿼리로 휴일을 제외한 근무일수 계산하기
[SQL] 서브쿼리로 휴일을 제외한 근무일수 계산하기
0. 목표 - 서브쿼리로 휴일을 제외한 근무일수 계산하기 1. 실습하기 1) 테이블 생성 (1) procedure_test CREATE TABLE sql_test.procedure_test ( id int, date1 datetime, date2 datetime ); (2) holiday CREATE TABLE sql_test.holiday ( holiday datetime ); 2) 데이터 삽입 INSERT INTO sql_test.procedure_test(id, date1, date2) VALUES(1, '2021-01-01 11:11:11', '2021-01-20 11:11:11'); INSERT INTO sql_test.procedure_test(id, date1, date2) VALUES(2,..
 [PYTHON] pandas query 함수 사용하기
[PYTHON] pandas query 함수 사용하기
0. 목표 - query 함수 사용하기 1. 실습하기 1) library 호출 import pandas as pd 2) dataframe 생성 df = pd.DataFrame({'A' : [1, 2, 3, 4, 5], 'B' : ['apple', 'banana', 'apple', 'berry', 'watermelon']}) 3) query 사용하기 (1) where A > 3 df.query('A > 3') (2) where A > 3 and A 3 and A < 5') (3) where A = 1 or A = 4 df.query('A == 1 or A == 4') (4) where A in (1, 3, 5) df.query("A in (1, 3, 5)") (5) wher..
 [SQL] FIRST_VALUE 를 활용한 가격이 가장 낮은 것의 아이디 구하기
[SQL] FIRST_VALUE 를 활용한 가격이 가장 낮은 것의 아이디 구하기
0. 목표 - FIRST_VALUE 를 활용한 가격이 가장 낮은 것의 아이디 구하기 1. 실습 1) 테이블 생성 CREATE TABLE sql_test.last_value_test ( id int, price int ); 2) 데이터 삽입 INSERT INTO sql_test.last_value_test(id, price) VALUES(1, 10); INSERT INTO sql_test.last_value_test(id, price) VALUES(2, 9); INSERT INTO sql_test.last_value_test(id, price) VALUES(3, 73); INSERT INTO sql_test.last_value_test(id, price) VALUES(4, 23); INSERT INTO s..
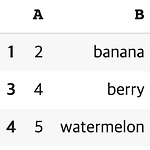 [PYTHON] isin 으로 SQL in, not in 구현
[PYTHON] isin 으로 SQL in, not in 구현
0. 목표 - isin 으로 SQL in 구현 1. 실습하기 1) library 호출 import pandas as pd 2) 테이블 생성 df = pd.DataFrame({'A' : [1, 2, 3, 4, 5], 'B' : ['apple', 'banana', 'apple', 'berry', 'watermelon']}) 3) isin 으로 in 구현 df[df.B.isin([1, 'apple'])] 4) isin 으로 not in 구현 df[~df.B.isin([1, 'apple'])] 2. 참고 - How to filter Pandas dataframe using 'in' and 'not in' like in SQL
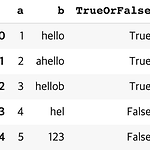 [PYTHON] lambda 와 정규표현식을 이용한 SQL like 구현
[PYTHON] lambda 와 정규표현식을 이용한 SQL like 구현
0. 목표 - lambda 와 정규표현식을 이용한 SQL like 구현 1. 실습 1) library 호출 import pandas as pd import re 2) 데이터 프레임 생성 df = pd.DataFrame({'a' : [1, 2, 3, 4, 5], 'b' : ['hello', 'ahello', 'hellob', 'hel', '123']}) 3) 함수 생성 - 정규식을 이용하여 결과가 re.Match 이면 True 반환 아니면 False 반환 def function(x, inp): p = re.compile(inp) m = p.search(x) return type(m) == re.Match 4) %hello% df['TrueOrFalse'] = df.apply(lambda x : functi..