
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Tistory
- matplotlib
- MATLAB
- tensorflow
- 서평
- Visualization
- MySQL
- 파이썬
- Ga
- 시각화
- 한빛미디어
- Python
- python visualization
- Blog
- 매틀랩
- 한빛미디어서평단
- 텐서플로
- Pandas
- 월간결산
- 리눅스
- Google Analytics
- 블로그
- 독후감
- 서평단
- SQL
- 티스토리
- 딥러닝
- 통계학
- Linux
- 파이썬 시각화
- Today
- Total
목록빅데이터 (65)
pbj0812의 코딩 일기
 [자동화] Airflow BashOperator 사용하기
[자동화] Airflow BashOperator 사용하기
0. 목표 - Airflow BashOperator 사용하기 1. flow chart - python 으로 빈 csv 파일을 만들고 그 python 파일을 bash 가 돌리고 그 bash 파일을 Airflow 의 BashOperator 를 이용하여 구동 2. python 파일 생성(make_csv.py) - 해당 위치에 test.csv 라는 빈 csv 파일 생성 def result(): f = open("/Users/pbj0812/Desktop/test_code/test_airflow/test.csv", "w") f.close() if __name__ == "__main__": result() 3. bash 파일 생성(make_csv.sh) - 2. 의 make_csv.py 를 돌리도록 생성 python..
 [자동화] Airflow 2.0 설치 & 사용자 계정 생성
[자동화] Airflow 2.0 설치 & 사용자 계정 생성
0. 목표 - Airflow 2.0 설치 & 사용자 계정 생성 1. Airflow 설치 & 실행 1) Airflow 설치 pip install apache-airflow 2) DB 초기화 airflow db init 3) airflow 실행 airflow webserver -p 8080 4) localhost:8080 - 이전버전에서는 볼 수 없던 로그인 창 생성 2. 유저 계정 생성 1) 계정 생성 - users create 라는 명령어를 사용하여 유저 생성 - 터미널에서 아래와 같은 방식으로 입력 - ROLE 에는 여러 종류가 있음(Admin, User, ...) airflow users create \ --username admin \ --firstname FIRST_NAME \ --lastname..
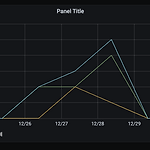 [빅데이터기술] Grafana + ElasticSearch 시계열 대쉬보드 생성
[빅데이터기술] Grafana + ElasticSearch 시계열 대쉬보드 생성
0. 목표 - Grafana + ElasticSearch 시계열 대쉬보드 생성 1. 실습 1) ElasticSearch 설치(링크) 및 데이터 생성(링크) 2) Grafana 설치 및 실행(링크) 3) Configuration -> Data Sources 4) Add data source -> Elasticsearch 5) 연결 - save and test 로 연결 확인 - ES 버전이 중요 - Time field 설정 6) Create -> Dashboard 7) Add new panel 8) 쿼리를 세개 만들어서 소년의 결과와 소녀의 결과와 전체의 결과를 시각화 9) 완성 - 9:00 기준으로 묶이는건 왜인가...
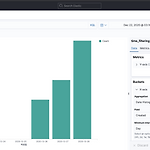 [빅데이터기술] Kibana에서 날짜를 기준으로 한 바 차트 생성
[빅데이터기술] Kibana에서 날짜를 기준으로 한 바 차트 생성
0. 목표 - Kibana에서 날짜를 기준으로 한 바 차트 생성 1. 데이터 삽입 1) library 호출 from elasticsearch import Elasticsearch from elasticsearch import helpers 2) ES 연결 es = Elasticsearch('http://127.0.0.1:9200') es.info() 3) 인덱스 생성 함수 def make_index(es, index_name): if es.indices.exists(index=index_name): es.indices.delete(index=index_name) es.indices.create(index=index_name) 4) 날짜 생성 - ES에서 인덱스 생성시 자동으로 날짜 포맷으로 인식하기 위해..
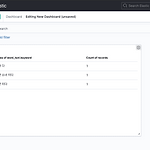 [빅데이터기술] ElasticSearch, Kibana에서 원하는 단어만 필터링하기
[빅데이터기술] ElasticSearch, Kibana에서 원하는 단어만 필터링하기
0. 목표 - ElasticSearch, Kibana에서 원하는 단어만 필터링하기 - ES, Kinbana 설치 및 실행 1. 데이터 생성 1) library 호출 from elasticsearch import Elasticsearch from elasticsearch import helpers 2) ES 연결 es = Elasticsearch('http://127.0.0.1:9200') es.info() 3) 인덱스 생성 함수 def make_index(es, index_name): if es.indices.exists(index=index_name): es.indices.delete(index=index_name) es.indices.create(index=index_name) 4) 테스트 데이터 i..
 [GA] Google Analytics 와 Data Studio 연동 및 대쉬보드 생성
[GA] Google Analytics 와 Data Studio 연동 및 대쉬보드 생성
0. 목표 - Google Analytics 와 Data Studio 연동 및 대쉬보드 생성 1. 실습 1) 빈 보고서 2) Google 애널리틱스 3) 승인 4) 추가 5) 보고서에 추가 6) 국가별 세션 수 7) 기기별 세션수, 이번분기 신규 방문자 vs 지난분기 신규 방문자 - 그래프 색 두개를 따로 지정할수는 없는듯... 세트로 묶임 8) 완성
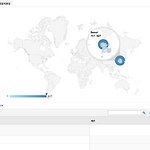 [GA] 블로그 포스트 맞춤 보고서 생성
[GA] 블로그 포스트 맞춤 보고서 생성
0. 목표 - GA 를 통한 포스트 방문자 맞춤 보고서 생성 1. 실습 1) 맞춤설정 -> 맞춤 보고서 2) + 새 맞춤 보고서 3) 플랫표 - 결과 4) 탐색기 - 결과 5) 방문자 분포 - 결과
 [빅데이터기술] docker 로 ElasticSearch + Kibana 연동 + python 연동을 통한 데이터 삽입 및 확인
[빅데이터기술] docker 로 ElasticSearch + Kibana 연동 + python 연동을 통한 데이터 삽입 및 확인
0. 목표 - docker 로 ElasticSearch + Kibana 연동 1. 도커 설정 1) elasticsearch docker 이미지 가져오기 docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.1 2) 컨테이너 실행 - 9200 포트 연결 docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.10.1 3) 실행 컨테이너 확인 docker ps 4) localhost:9200 5) kibana docker 이미지 가져오기 docker pull docker.elastic.co/k..
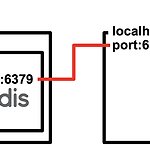 [빅데이터기술] Docker redis 컨테이너 생성 및 jupyter notebook 에서 실행
[빅데이터기술] Docker redis 컨테이너 생성 및 jupyter notebook 에서 실행
0. 목표 - Docker redis 설치 및 jupyter notebook 에서 설치 - 플로우 차트 1. 실습 1) redis (1) redis container 생성 - redis 이미지를 이용하여 컨테이너의 6379 포트를 외부(localhost)의 6379 포트와 연결 docker run -d -p 6379:6379 redis (2) container 실행 확인 docker ps 2) python (1) redis library 설치 pip install redis (2) library 호출 import redis (3) redis 연결 r = redis.Redis(host='localhost', port=6379, db=0) (4) 데이터 삽입 r.set('foo', 'bar') (5) 데이터..
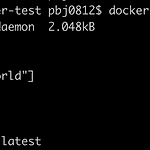 [빅데이터기술] Docker 이미지 파일 생성
[빅데이터기술] Docker 이미지 파일 생성
0. 목표 - Docker 이미지 파일 생성 1. 실습 1) Dockerfile 생성 - 파일명 Dockerfile - alpine 이미지 사용 - 결과 : hello world 출력 FROM alpine CMD ["echo", "hello world"] 2) 빌드 - 현재 폴더에서 Dockerfile 을 찾아 빌드하고 이름은 pbj0812/test 로 지정, latest 는 버전 docker build ./ -t pbj0812/test:latest 3) 생성 이미지 확인 - 두 개 있는 이유는 그냥 하나 더 만들은거... docker images 4) 컨테이너 실행 docker run -it pbj0812/test 2. 참고 - 따라하며 배우는 도커와 CI환경