
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 한빛미디어
- Linux
- 블로그
- 텐서플로
- 리눅스
- Google Analytics
- 월간결산
- SQL
- 한빛미디어서평단
- MySQL
- 딥러닝
- Blog
- Visualization
- 서평단
- Pandas
- 독후감
- 티스토리
- matplotlib
- MATLAB
- 서평
- 통계학
- 파이썬
- 매틀랩
- 시각화
- tensorflow
- Tistory
- 파이썬 시각화
- Ga
- Python
- python visualization
Archives
- Today
- Total
pbj0812의 코딩 일기
[빅데이터기술] Kibana에서 날짜를 기준으로 한 바 차트 생성 본문
0. 목표
- Kibana에서 날짜를 기준으로 한 바 차트 생성
1. 데이터 삽입
1) library 호출
from elasticsearch import Elasticsearch
from elasticsearch import helpers2) ES 연결
es = Elasticsearch('http://127.0.0.1:9200')
es.info()3) 인덱스 생성 함수
def make_index(es, index_name):
if es.indices.exists(index=index_name):
es.indices.delete(index=index_name)
es.indices.create(index=index_name)4) 날짜 생성
- ES에서 인덱스 생성시 자동으로 날짜 포맷으로 인식하기 위해 미리 datetime 형태로 넣어줌
from datetime import datetime
date1 = '12/26/20 10:12:13'
date2 = '12/26/20 10:13:13'
date3 = '12/27/20 10:12:13'
date4 = '12/27/20 10:12:13'
date5 = '12/27/20 10:12:13'
date6 = '12/28/20 10:12:13'
date7 = '12/28/20 11:12:13'
date8 = '12/28/20 12:12:13'
date9 = '12/28/20 13:12:13'
date10 = '12/28/20 14:12:13'
cre1 = datetime.strptime(date1, '%m/%d/%y %H:%M:%S')
cre2 = datetime.strptime(date2, '%m/%d/%y %H:%M:%S')
cre3 = datetime.strptime(date3, '%m/%d/%y %H:%M:%S')
cre4 = datetime.strptime(date4, '%m/%d/%y %H:%M:%S')
cre5 = datetime.strptime(date5, '%m/%d/%y %H:%M:%S')
cre6 = datetime.strptime(date6, '%m/%d/%y %H:%M:%S')
cre7 = datetime.strptime(date7, '%m/%d/%y %H:%M:%S')
cre8 = datetime.strptime(date8, '%m/%d/%y %H:%M:%S')
cre9 = datetime.strptime(date9, '%m/%d/%y %H:%M:%S')
cre10 = datetime.strptime(date10, '%m/%d/%y %H:%M:%S')5) 데이터 제작
index_name = 'time_filtering2'
doc1 = {'word_text': '나는 소년 이다', 'Created': cre1}
doc2 = {'word_text': '나는 소년 이다', 'Created': cre2}
doc3 = {'word_text': '나는 소년 소녀 이다', 'Created': cre3}
doc4 = {'word_text': '나는 소녀 이다', 'Created': cre4}
doc5 = {'word_text': '나는 소년 이다', 'Created': cre5}
doc6 = {'word_text': '나는 소년 이다', 'Created': cre6}
doc7 = {'word_text': '나는 소년 소년 이다', 'Created': cre7}
doc8 = {'word_text': '나는 소년 이다', 'Created': cre8}
doc9 = {'word_text': '나는 소년 이다', 'Created': cre9}
doc10 = {'word_text': '나는 소녀 이다', 'Created': cre10}6) 인덱스 생성
make_index(es, index_name)7) 데이터 삽입
es.index(index=index_name, doc_type = 'log', body=doc1)
es.index(index=index_name, doc_type = 'log', body=doc2)
es.index(index=index_name, doc_type = 'log', body=doc3)
es.index(index=index_name, doc_type = 'log', body=doc4)
es.index(index=index_name, doc_type = 'log', body=doc5)
es.index(index=index_name, doc_type = 'log', body=doc6)
es.index(index=index_name, doc_type = 'log', body=doc7)
es.index(index=index_name, doc_type = 'log', body=doc8)
es.index(index=index_name, doc_type = 'log', body=doc9)
es.index(index=index_name, doc_type = 'log', body=doc10)2. Kibana 설정
1) Manage

2) Index Patterns

3) Create index pattern

4) 해당 패턴 검색 및 Next step
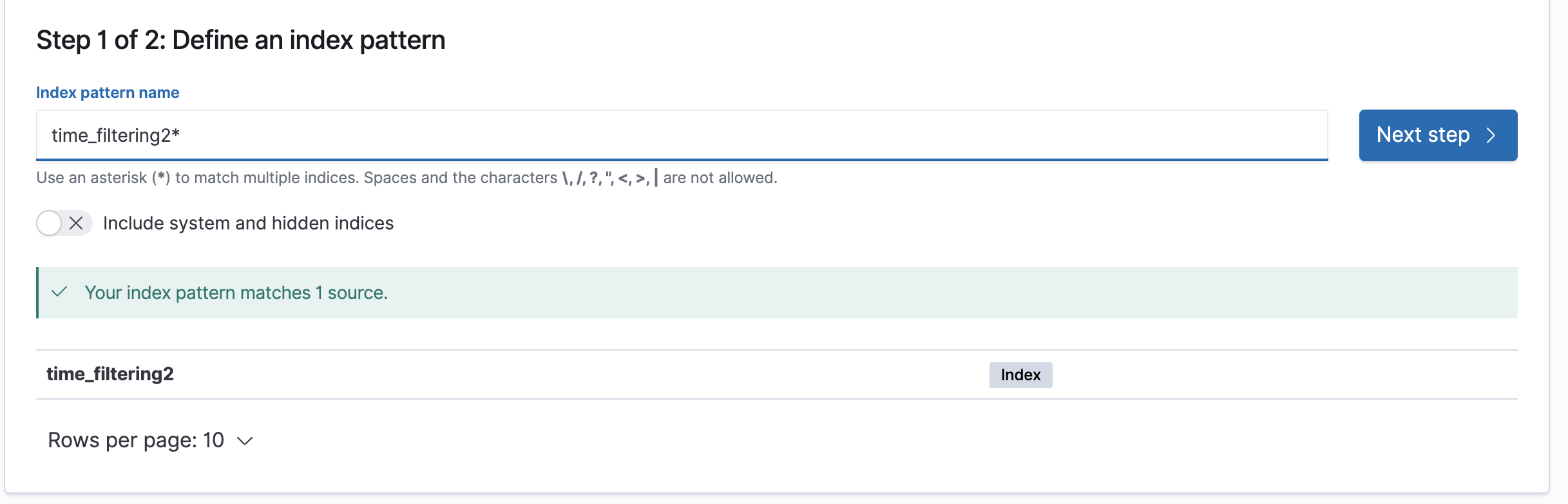
5) Time filed 지정
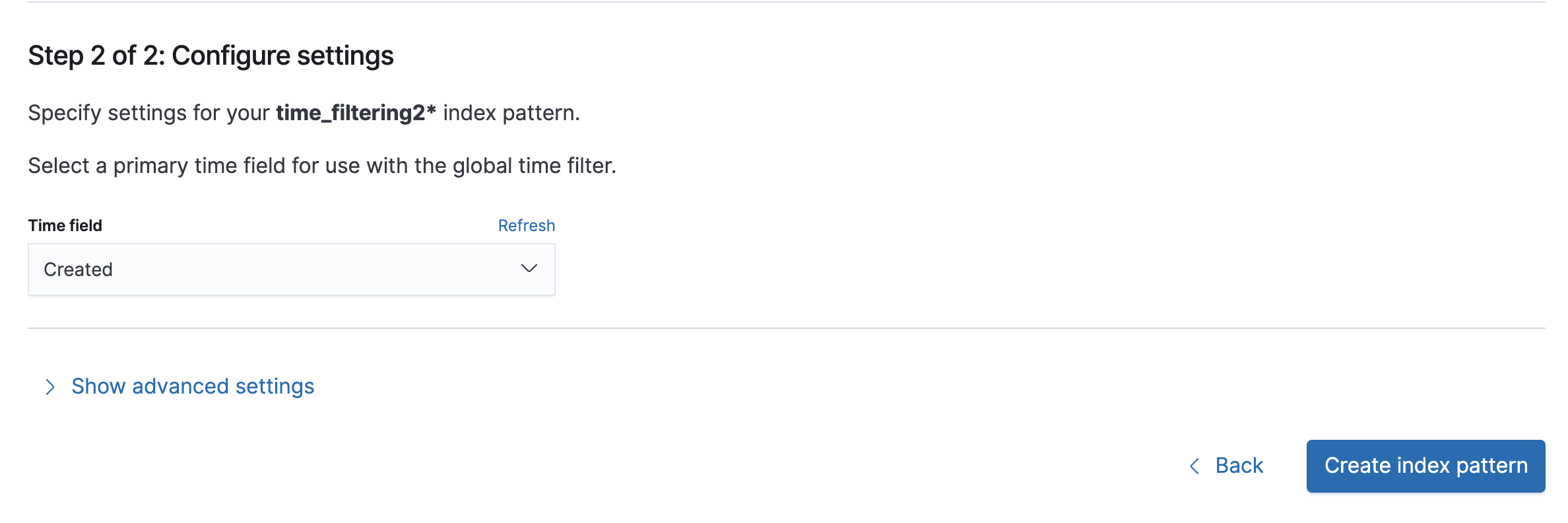
6) Created 의 Type 확인(date)

7) Visualizations -> Create visualization

8) Vertical Bar

9) Buckets 을 X-axis 로 놓고 조작

3. 참고
'빅데이터 > 빅데이터기술' 카테고리의 다른 글
| [빅데이터기술] DBT 설치 및 MySQL 에 연결 해보기 (0) | 2024.02.27 |
|---|---|
| [빅데이터기술] Grafana + ElasticSearch 시계열 대쉬보드 생성 (0) | 2020.12.30 |
| [빅데이터기술] ElasticSearch, Kibana에서 원하는 단어만 필터링하기 (0) | 2020.12.25 |
| [빅데이터기술] docker 로 ElasticSearch + Kibana 연동 + python 연동을 통한 데이터 삽입 및 확인 (0) | 2020.12.19 |
| [빅데이터기술] Docker redis 컨테이너 생성 및 jupyter notebook 에서 실행 (0) | 2020.12.13 |
'빅데이터/빅데이터기술' Related Articles
more




Comments