
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Visualization
- 한빛미디어서평단
- tensorflow
- MySQL
- 파이썬
- MATLAB
- 한빛미디어
- 리눅스
- 티스토리
- Google Analytics
- 파이썬 시각화
- Linux
- 통계학
- 서평단
- 시각화
- SQL
- 매틀랩
- Tistory
- Ga
- 블로그
- 독후감
- 월간결산
- 딥러닝
- 서평
- 텐서플로
- Python
- Blog
- matplotlib
- Pandas
- python visualization
- Today
- Total
목록파이썬 (184)
pbj0812의 코딩 일기
 [kaggle] Intro to Deep Learning 수료과정
[kaggle] Intro to Deep Learning 수료과정
0. 목차 및 내용 1) A Single Neuron - 뉴런 설명 - keras.Sequential 을 이용한 인풋 설계까지 2) Deep Neural Networks - 활성화 함수, ReLU, 레이어 쌓기 3) Stochastic Gradient Descent - 로스 함수, 옵티마이저, 학습률, 배치 사이즈 4) Overfitting and Underfitting - 언더피팅, 오버피팅, - 적정한 구간을 찾기 위한 Early Stopping - 문제 도중에 csv 가 없다는 일이 발생하였는데 아래 그림과 같이 우상단의 add data 를 누르고 spotify.csv 를 받은 이후 위치 설정하면 해결 5) Dropout and Batch Normalization - 드롭아웃 - Batch Norm..
 [kaggle] Data Cleaning 수료과정
[kaggle] Data Cleaning 수료과정
0. 목차 및 내용 1) Handling Missing Values - NULL 이 포함된 데이터에 대한 처리 - dropna() 를 통한 행 제외 - dropna(axis=1) 를 통한 열 제외 - fillna(0) 를 통한 처리 - fillna(method='bfill', axis=0).fillna(0) 를 통한 대체 2) Scaling and Normalization - Scaling 과 Normalization 의 차이(Scaling 은 값의 범위를 바꾸는 것?, 1달러와 1엔의 예를 들었을 때 1달러는 100엔의 가치가 있음. 이때, Scaling 을 하지 않으면 1엔의 차이와 1달러의 차이는 비슷해짐. Normalization 은 데이터 분포의 형태를 바꾸는 것?) - mlxtend.prepr..
 [kaggle] pandas 수료과정
[kaggle] pandas 수료과정
0. 목차 및 내용 1) Creating, Reading and Writing - DataFrame 제작 방법(개인적으로는 dict 형태로만 썼었는데, 아래와 같이 쓸 수도 있음) fruit_sales = pd.DataFrame([[35, 21], [41, 34]], columns=['Apples', 'Bananas'], index=['2017 Sales', '2018 Sales']) - Series 에 관한 설명 - read_csv 를 통한 csv 파일 읽기 2) Indexing, Selecting & Assigning - iloc과 loc의 차이(iloc 은 stdlib indexing 기반 이기에 0:10 의 결과가 10개 나오지만 loc 은 11개가 나옴) - 해당 조건에 맞는 결과 추출 - 열 ..
 [SQL] Procedure 를 통한 임시 데이터 보관 테이블 생성
[SQL] Procedure 를 통한 임시 데이터 보관 테이블 생성
0. 목표 - Procedure 를 통한 임시 데이터 보관 테이블 생성 1. Flow Chart 2. SQL 1) 테이블 생성 (1) sp_test1(raw table 저장소) CREATE TABLE pbj_db.sp_test1 ( datetime datetime, result int ) ENGINE = INNODB; (2) sp_test2(임시 데이터 저장소) CREATE TABLE pbj_db.sp_test2 ( datetime datetime, result int ) ENGINE = INNODB; 2) 프로시저 생성 - 실행시 1분 전의 데이터들을 모아서 연산 DELIMITER $$ CREATE PROCEDURE pbj_db.what_time_is_it_now() BEGIN # 지우기 DELETE ..
 [PYTHON] HATCH 를 통한 bar 그래프에 문양 넣기
[PYTHON] HATCH 를 통한 bar 그래프에 문양 넣기
1. 목표 - HATCH 를 통한 bar 그래프에 문양 넣기 * 주의사항 : matplotlib 3.4.0 버전 신규 기능(링크) 2. 실습 1) matplotlib 업데이트 - jupyter notebook 내에서 업데이트를 하였기에 앞에 ! 붙임 !pip install --upgrade matplotlib 2) library 호출 import matplotlib.pyplot as plt 3) hatch 를 통한 bar에 문양 적용 - *+-./OX\ox| 적용 가능 fig, ax = plt.subplots() ax.bar(1, 1, hatch=['*']) plt.show() (1) * (2) + (3) - (4) . (5) / (6) O(대문자) (7) X(대문자) (8) \ - '\' 이렇게 하면 ..
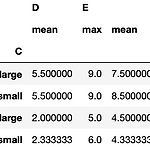 [Python] Pandas pivot, pivot_table 문서 따라하기
[Python] Pandas pivot, pivot_table 문서 따라하기
0. 목표 - pivot, pivot_table 문서 따라하기 1. pivot 1) library 호출 import pandas as pd 2) 데이터 생성 df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two', 'two'], 'bar': ['A', 'B', 'C', 'A', 'B', 'C'], 'baz': [1, 2, 3, 4, 5, 6], 'zoo': ['x', 'y', 'z', 'q', 'w', 't']}) 3) - foo 를 행기준으로 bar 를 열 기준으로 baz 를 채워넣기 df.pivot(index='foo', columns='bar', values='baz') 4) - 3) 과 동일한 결과 df.pivot(index='foo', col..
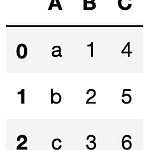 [Python] pandas melt 도큐먼트 따라하기
[Python] pandas melt 도큐먼트 따라하기
0. 묵표 - pandas melt 도큐먼트 따라하기 1. 실습 1) library 호출 import pandas as pd 2) 데이터 생성 df = pd.DataFrame({'A' : ['a', 'b', 'c'], 'B' : [1, 2, 3], 'C' : [4, 5, 6]}) 3) melt 예제 따라하기 (1) pd.melt(df, id_vars=['A'], value_vars=['B']) (2) pd.melt(df, id_vars=['A'], value_vars=['C']) (3) pd.melt(df, id_vars=['A'], value_vars=['B', 'C']) (4) 필드명 변경 pd.melt(df, id_vars = ['A'], value_vars = ['B'], var_name = 'v..
 [Python] 쿼리가 기록된 txt 파일을 이용한 쿼리 실행(pymysql)
[Python] 쿼리가 기록된 txt 파일을 이용한 쿼리 실행(pymysql)
0. 플로우 차트 - 쿼리가 작성된 txt 를 읽어 해당 쿼리를 이용해 MySQL 에서 데이터를 가져온 뒤 pandas 의 DataFrame 형태로 출력 1. 텍스트 파일 내용 SELECT * FROM pbj_db.rownum_test; 2. 실습 1) library 호출 import pymysql import pandas as pd 2) db 연결 db = pymysql.connect(host='127.0.0.1', port=3306, user='root', db='pbj_db', charset='utf8', cursorclass=pymysql.cursors.DictCursor) cursor = db.cursor() 3) 파일 읽기 f = open("./sql.txt", 'r') sql = '' whi..
0. 목표 - 문서의 모든 행의 끝부분마다 문자 넣기 1. 데이터 준비 select a.userId FROM User AS A; 2. 코드 작성 - f 에서는 원본의 txt 파일을 가져온다. - f2 에서는 변환된 정보를 txt 파일로 기록한다. - readline 을 통하여 한 줄씩 읽어서 line에 담는다. - a 변수에는 line을 str의 형태로 담아준다. - aa 변수에는 \n 을 구분으로 나누어 개행을 기준으로 분류한다. - aaa 변수에는 개행을 제외한 문자와 새로 추가될 문자들을 더한 뒤 마지막에 \n 을 추가하여 개행을 한다. - f2 에 aaa를 담는다. f = open("./sql.txt", 'r') f2 = open('./sql2.txt', 'w') while True: line =..
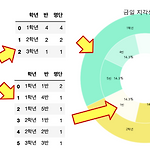 [PYTHON] 자동화 Pie-Donut 차트 만들기
[PYTHON] 자동화 Pie-Donut 차트 만들기
0. 목표 - 자동화 Pie-Donut 차트 만들기 1. 기존의 Pie-Donut 차트 분석 - 기존 원본 링크 - 기존에는 숫자, 사이즈, 명암을 사람의 손으로 구해야 되어서 불편함이 많음 2. FlowChart 3. 실습 1) library 호출 - 차트에 한글을 넣기 위한 rc 호출(mac) import pandas as pd import random import numpy as np from matplotlib import rc rc('font', family='AppleGothic') 2) 데이터 생성 df = pd.DataFrame({'학년' : ['1학년', '2학년', '3학년', '1학년', '2학년', '1학년', '1학년'], '반' : ['1반', '2반', '3반', '4반', '..