
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- MySQL
- Blog
- tensorflow
- SQL
- 매틀랩
- 티스토리
- 서평
- python visualization
- 파이썬 시각화
- 월간결산
- 시각화
- 서평단
- Ga
- 한빛미디어서평단
- Pandas
- 텐서플로
- MATLAB
- Linux
- 딥러닝
- 통계학
- 독후감
- 한빛미디어
- Tistory
- 리눅스
- 파이썬
- Python
- Google Analytics
- matplotlib
- Visualization
- 블로그
- Today
- Total
목록파이썬 (184)
pbj0812의 코딩 일기
0. 예제 - 아래 예제에서 zoo 라는 변수에 cage 라는 이름의 namedtuple 을 할당했지만 zoo 라는 변수에 할당된 namedtuple 은 cage 가 아닌 zoo 라는 이름을 가짐. => 일반적으로 namedtuple 의 첫 번째 매개변수로 정의되는 이름은 변수 이름과 일치시키는 것이 좋음(가독성, 유지보수 용이) from collections import namedtuple zoo = namedtuple('cage', ['animal', 'price']) result = zoo('tiger', 3000) print(result.animal, result.price) tiger 3000 출력 def print_zoo(animal, price): print(animal, price) pri..
0) 예제1 - 튜플의 값들을 변수 하나씩 지정 data = (1, 2, 3) n1, n2, n3 = data[0], data[1], data[2] print(n1, n2, n3) 1 2 3 출력 - 언패킹을 사용하면 한 번에 가능 data = (1, 2, 3) n1, n2, n3 = data print(n1, n2, n3) 1 2 3 출력 - 리스트도 가능 data2 = [1, 2, 3] n11, n22, n33 = data2 print(n11, n22, n33) 1 2 3 출력 1) 예제2 - * 를 사용하면 low 에 1, high 에 6이 배정되고 others 에 [2, 3, 4, 5] 가 배정됨 scores = (1, 2, 3, 4, 5, 6) low, *others, high = scores ..
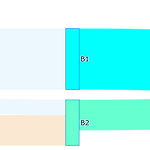 [PYTHON] plotly 를 이용하여 sankey diagram 그리기(+ 색상 추가)
[PYTHON] plotly 를 이용하여 sankey diagram 그리기(+ 색상 추가)
0. 목표 - plotly 를 이용하여 sankey diagram 그리기(+ 색상 추가) 1. 실습 1) library 호출 import plotly.graph_objects as go import pandas as pd import matplotlib.colors as mcolors 2) 데이터 생성 df = pd.DataFrame({ 'source' : ['A1', 'A1', 'A2', 'B1', 'B2'], 'target' : ['B1', 'B2', 'B2', 'C1', 'C1'], 'value' : [8, 2, 4, 8, 4] }) 3) 라벨 만들기 label = pd.DataFrame({ 'name' : ['A1', 'A2', 'B1', 'B2', 'C1'], 'code' : [0, 1, 2, ..
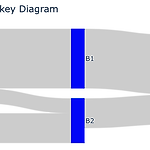 [PYTHON] plotly 를 통해 sankey diagram 그리기
[PYTHON] plotly 를 통해 sankey diagram 그리기
0. 목표 - plotly 를 통해 sankey diagram 그리기 1. 실습 1) library 호출 import plotly.graph_objects as go import pandas as pd 2) 데이터 생성 df = pd.DataFrame({ 'source' : ['A1', 'A1', 'A2', 'B1', 'B2'], 'target' : ['B1', 'B2', 'B2', 'C1', 'C1'], 'value' : [8, 2, 4, 8, 4] }) 3) 라벨용 데이터 생성 label = pd.DataFrame({ 'name' : ['A1', 'A2', 'B1', 'B2', 'C1'], 'code' : [0, 1, 2, 3, 4] }) 4) 매핑 dict_sido = label.set_index(..
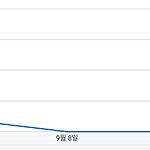 [PYTHON] OpenCV 를 활용한 그래프의 y 좌표 구하기
[PYTHON] OpenCV 를 활용한 그래프의 y 좌표 구하기
0. 문제 - 아래와 같은 그림이 하나 주어졌을때 각 x 좌표에 대한 y 값들을 구하기 1. 실습 1) library 호출 import cv2 import numpy as np import matplotlib.pyplot as plt 2) 이미지 가져오기 image = cv2.imread('/content/drive/MyDrive/96__코드/test2.png') 3) 이미지 크기 및 파란색 좌표 따오기 length = np.shape(image)[1] # 가로 길이 length2 = np.shape(image)[0] # 세로 길이 blue = [222, 104, 0] # 파란색 BGR(좌표 찍어서 찾음) image2 = image.reshape(-1, 3) # 데이터를 한 줄로 만들기 indices..
0. 이론 - 준비한 데이터에서 복원 추출을 반복해 많은 재표본을 생성하고, 그 통계량에서 모수를 추정 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import pandas as pd import random import statistics 2) 데이터 생성 - t 분포 를 활용한 신뢰구간 : 1.03 ~ 4.97 x = [1, 2, 3, 4, 5] print('신뢰구간 : ', round(np.mean(x) - 2.78 * 0.71, 2), ' ~ ', round(np.mean(x) + 2.78 * 0.71, 2)) 3) 부트스트랩 - 5개씩 뽑아서(복원추출) 평균을 만들고 해당 데이터들을 통해 신뢰구간 구현 var = ..
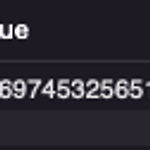 [통계학] python, sql 로 t-test 구현
[통계학] python, sql 로 t-test 구현
0. 목표 - python, sql 로 t-test 구현 1. 실습 1) scipy - Ttest_indResult(statistic=-3.0869745325651587, pvalue=0.031361515666731996) import numpy as np import scipy.stats x = [1, 2, 3, 4, 5] y = [4, 8, 12, 16, 20] mean_x = np.mean(x) mean_y = np.mean(y) print('x : ', mean_x) print('y : ', mean_y) scipy.stats.ttest_ind(x, y, equal_var=False) 2) 그냥 파이썬 - -3.0869745325651587 import numpy as np import math ..
 [독후감] 혼자 공부하는 데이터 분석 with 파이썬
[독후감] 혼자 공부하는 데이터 분석 with 파이썬
"한빛미디어 활동을 위해서 책을 제공받아 작성된 서평입니다." 1. 도서 정보 - 도서명 : 혼자 공부하는 데이터 분석 with 파이썬 - 저자 : 박해선 - 링크 2. 후기 - 제목처럼 파이썬을 통한 데이터 분석 입문용으로는 추천할 수 있다. 기본 환경 세팅인 코랩 설치를 시작으로 csv, api 를 통한 데이터 수집 및 크롤링을 통한 데이터 수집 방법도 기술되어 있다. 데이터 분석 방법으로는 기본적인 판다스 라이브러리 사용 및 기초 통계(중앙값, 표준편차), 간단한 시각화 방법도 기술되어 있다. 그렇기에 데이터 분석에 대한 절차를 알아보기에는 좋은 책이라고 할 수 있으나... 넓은 분야를 다루다보니 깊이가 깊을수는 없기에 이미 데이터 분석을 할 수 있으신 분들께는 추천드리지 않으며 또한, 파이썬도 모..
 [통계학] z-score 를 python, MySQL 로 구현하기
[통계학] z-score 를 python, MySQL 로 구현하기
0. 목표 - z-score 를 python, MySQL 로 구현하기 1. 이론 - 데이터의 평균을 0.0 으로 표준편차를 1.0 으로 만드는 기법 2. 구현 1) scipy 로 구현 from scipy import stats x = [i for i in range(1, 10)] z_score = stats.zscore(x) print(z_score) 2) 그냥 python 으로 구현 import math x = [i for i in range(1, 10)] len_x = len(x) # 길이 x_mean = sum(x) / len_x # 평균 x_var = 0 for i in x: x_var += (i - x_mean) ** 2 x_var = x_var / len_x # 분산 x_std = math.s..
 [PYTHON] PyScript 로 그림 그리기
[PYTHON] PyScript 로 그림 그리기
0. 작업 준비 - 파일 확장자는 html 로 한다. 1. 코드 작성 - link, script 는 복붙하면 된다. - py-config 에는 불러올 라이브러리를 적는다. - py-script 에 본문을 적는다. - 마지막에 쓴 display 함수를 통해 그릴 곳을 지정한다. - id = graph-area 확인 packages = ["matplotlib", "numpy"] import numpy as np import matplotlib.pyplot as plt from matplotlib.patches import Ellipse, Polygon x = -1 y = abs(x) * np.tan(1/3 * np.pi) y_1 = 1/3 * y y_2 = 2/3 * y data = [1, 1, 2] n =..