
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Visualization
- 리눅스
- 서평단
- 파이썬 시각화
- Pandas
- Blog
- tensorflow
- 블로그
- 티스토리
- Python
- 매틀랩
- 월간결산
- 한빛미디어
- 통계학
- Ga
- 파이썬
- 서평
- Linux
- Tistory
- matplotlib
- 시각화
- MATLAB
- Google Analytics
- 텐서플로
- python visualization
- MySQL
- 한빛미디어서평단
- 독후감
- SQL
- 딥러닝
- Today
- Total
목록분류 전체보기 (596)
pbj0812의 코딩 일기
 [수학] python으로 유클리드 거리 계산하기
[수학] python으로 유클리드 거리 계산하기
0. 목표 - python으로 유클리드 거리 계산하기 1. 기본 이론 - 링크 2. 실습 1) library 호출 import numpy as np import pandas as pd 2) 제곱근 함수 제작 - 에러 발생시(입력값이 0인 경우) 결과값이 0으로 출력 def sqrt(inp): result = inp/2 for i in range(30): try: result = (result + (inp / result)) / 2 except: result = 0 return result 3) 유클리드거리 계산 함수 제작 - 이중 for문을 통하여 모든 리스트 값이 한번씩 마주치면서 유클리드 거리 계산을 한 뒤 데이터 프레임의 형태로 출력 def euclidean(inp): result = [] len_..
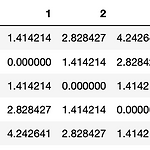
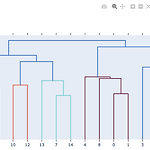 [PYTHON] plotly를 이용한 dengrogram 그리기
[PYTHON] plotly를 이용한 dengrogram 그리기
0. 목표 - plotly를 이용한 dengrogram 작성 1. 실습 1) 설치 pip install plotly 2) library 호출 import plotly.figure_factory as ff import numpy as np 3) 데이터 생성 - 단순 list로 데이터 생성시 에러 발생 - 최소 2개 이상의 데이터가 필요 - [1, 2, 3]의 형태가 아닌 [[1], [2], [3]]의 형태로 들어가야 함 np.random.seed(1) X = np.random.rand(15, 12) 4) 덴드로그램 생성 - 그림이 아닌 상호작용이 가능한 gui 생성 fig = ff.create_dendrogram(a) fig.update_layout(width=800, height=500) fig.show..
 [마케팅] 티스토리 블로그에 애드센스 달기 (2/2)
[마케팅] 티스토리 블로그에 애드센스 달기 (2/2)
0. 목표 - 티스토리 블로그에 애드센스 달기 1. 지난시간 - 사이트 검토 대기중 (링크) 2. 실습 1) 이틀 뒤... - 승인요청 메일 도착 2) 애드센스 접속 - 링크 3) 광고 -> 개요 -> 광고 단위 기준 -> 인피드 광고 4) 페이지 주소 입력 -> 페이지 스캔하기 - 내 페이지 접속자의 95% 이상이 데스크톱이기에 데스크톱 선택 5) 다음 6) 저장 및 코드 생성 7) 코드 복사 8) 티스토리 -> 플러그인 -> 구글 애드센스(반응형) -> 내용 붙여 넣기 -> 변경사항 적용 2. 결과
0. 목표 - 가우스 조던 소거법을 통한 연립방정식 계산(python 사용) - 아래식의 해 도출 y -3z = -5 2x + 3y -z = 7 4x + 5y - 2z = 10 1. 이론 - 예제 링크 2. 실습 1) library 호출 import numpy as np import copy 2) 데이터 생성 - x, y, z 순서대로 a 행렬 생성 * .0을 붙이지 않고 정수 형태로 만들경우 뒷 부분의 나눗셈 부분에서 정수로 떨어짐 a = np.array([[0.0, 1.0, -3.0], [2.0, 3.0, -1.0], [4.0, 5.0, -2.0]]) b = np.array([[-5.0], [7.0], [10.0]]) 3) 확인용 함수 def check(a, b): print(a) print('===..
0. 목표 - python을 이용한 U 값 계산 - U 값 : 두 집단을 순위 데이터로 변환하여 분포가 겹치는 정도를 나타내는 통계량 1. 방법 1) 데이터를 양 집단을 합친 순위로 변환 2) 양 집단을 합쳐서 작은순으로 순서를 붙임 3) A 집단보다 작은 B 직단의 개수를 계산하고 그 값을 합산한 값이 U 값 2. 구현 1) 두 집단(데이터) 생성 a = [10.2, 8.3, 5.1, 3.4] b = [90.0, 10.2, 7.7, 6.8, 4.0] 2) 두 집단(데이터)을 하나로 합침 - [10.2, 8.3, 5.1, 3.4, 90.0, 10.2, 7.7, 6.8, 4.0] total = a + b print(total) 3) 순서 정렬 - [3.4, 4.0, 5.1, 6.8, 7.7, 8.3, 10..
 [R] explore 라이브러리를 통한 EDA
[R] explore 라이브러리를 통한 EDA
0. 목표 - explore 라이브러리를 통한 EDA 1. 실습 1) 설치 install.packages("explore") 2) library 호출 library(explore) 3) csv 읽기 - 캐글의 타이타닉 데이터 df
 [마케팅] 티스토리 블로그에 애드센스 달기 (1/2)
[마케팅] 티스토리 블로그에 애드센스 달기 (1/2)
0. 목표 - 티스토리 블로그에 구글 애드센스 달기 1. 애드센스 정보 획득 1) 구글 애드센스 접속 - 우상단의 시작하기 2) 내용 작성을 통한 계정 생성 * 중간에 뭔가 튕긴다면 다시 시작하기 버튼 눌러서 작성 3) 개인정보 작성 및 제출 4) 애드센스 코드 획득 2. 티스토리 설정 1) 설정 -> 플러그인 -> 애드센스 검색 -> 반응형 클릭 2) 원하는 형태 선택 및 1. 4)에서 획득한 애드센스 코드 붙여넣기 -> 적용 3) 1.4) 의 맨 마지막 부분의 체크 및 확인 - 결과 대기중...
 [통계학] spicy 패키지를 이용한 동전 던지기(베이지안)
[통계학] spicy 패키지를 이용한 동전 던지기(베이지안)
0. 목표 - scipy 패키지를 이용한 동전 던지기 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import matplotlib from IPython.core.pylabtools import figsize from matplotlib import rc import scipy.stats as stats 2) 함수 제작 - stats.beta : 베타분포 객체 생성(링크) - stats.bernoulli.rvs(0.5, size = inp[-1]) : 베르누이 시뮬레이션(확률 0.5로 계산, inp[-1]로 지정한 것은 리스트(숫자가 커지는 형태)로 받아서 돌릴때 가장 마지막 값(가장 긴 값)을 근거해서 그림을 그릴 것이기..
 [통계학] 몬테 카를로 방법을 통한 원의 넓이 계산(python)
[통계학] 몬테 카를로 방법을 통한 원의 넓이 계산(python)
0. 목표 - 몬테 카를로 방법을 통한 원의 넓이 계산 1. 실습 1) library 호출 import random import matplotlib.pyplot as plt 2) 인풋 데이터 제작 함수 - x와 y가 -1 ~ 1 사이의 랜덤한 실수 생성 - x**2 + y**2 가 1보다 작을 경우 원의 넓이에 포함되게 리스트에 넣어줌 def monte(inp): circle = 0 non_circle = 0 circle_x = [] circle_y = [] non_circle_x = [] non_circle_y = [] for i in range(inp): x = random.uniform(-1, 1) y = random.uniform(-1, 1) if (x**2) + (y**2)
 [통계학] python을 이용한 블로그 방문자수 회귀선 그리기
[통계학] python을 이용한 블로그 방문자수 회귀선 그리기
* 주의 : 이 데이터는 회귀를 사용하기에는 좋은 데이터가 아닙니다!!! 0. 목표 - python을 이용한 내 블로그 방문자 수 회귀선 그리기 - Y = a + bX (링크) 1. 실습 1) library 호출 import matplotlib.pyplot as plt 2) 데이터 생성 - y : 블로그를 다시 쓰기 시작한 2019년 2월 부터의 방문자수를 사용 - x : 2019년 2월을 1로 두고 1씩 증가하는 형태 y = [98, 221, 221, 419, 440, 451, 531, 523, 699, 612, 977, 1002, 1263, 1531, 2174, 3320, 3758, 5161] x = [i for i in range(1, len(y) + 1)] 3) 데이터 확인 plt.bar(x, y..