
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Blog
- MySQL
- 딥러닝
- 블로그
- 티스토리
- Pandas
- matplotlib
- 매틀랩
- 서평단
- Python
- Linux
- 시각화
- 파이썬 시각화
- MATLAB
- Google Analytics
- SQL
- 월간결산
- python visualization
- 리눅스
- 파이썬
- 한빛미디어
- Ga
- Tistory
- 통계학
- tensorflow
- 텐서플로
- 독후감
- 서평
- Visualization
- 한빛미디어서평단
- Today
- Total
목록분류 전체보기 (596)
pbj0812의 코딩 일기
0. 목표 - python을 이용한 부트스트랩 구현 1. 이론 1) 샘플 값을 하나 뽑아서 기록하고 제자리에 놓는다. 2) n번 반복한다. 3) 재표본추출된 값의 평균을 길록한다. 4) 1~3단계를 R번 반복한다. 5) R개의 결과를 사용하여 (1) 표준편차 계산 (2) 히스토그램 or 상자그림 (3) 신뢰구간 찾기 2. 실습 1) library 호출 import numpy as np 2) 평균 def mean(inp): result = 0 len_inp = len(inp) for i in inp: result += i result = result / len_inp return result 3) 모수생성 - 정규 분포를 따르는 백만개의 수 생성 mom = list(np.random.normal(size ..
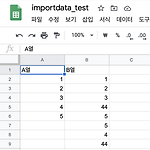 [자동화] importrange를 통한 스프레드시트 내용 복사
[자동화] importrange를 통한 스프레드시트 내용 복사
0. 목표 - google spreadsheet의 importrange 함수를 통한 스프레드시트 내용의 복사 1. 함수 사용 방법 - 메뉴얼 - IMPORTRANGE("시트주소", "범위") * importdata 함수의 경우 한 스프레드시트에서 최대 50개의 importdata 함수를 호출할 수 있었다고 하나, 새로운 버전에서는 한도가 삭제되었다고 함 2. 실습 1) 실습 데이터 생성 2) 새로운 시트 생성 - A1셀에 함수 적용 =importrange("https://docs.google.com/spreadsheets/d/시트url", "시트1!A:B") - 결과 * 주의사항 - 해당범위내에 문자 입력시 에러 발생 3. 참고 - 공식 메뉴얼
 [SQL] MySQL 예외처리(exception)
[SQL] MySQL 예외처리(exception)
0. 목표 - MySQL exception을 통한 예외처리 1. 실습 1) 에러 확인을 위한 프로시저 생성 - pbj_db.abcdefghijklmnop 테이블에 현재 시각을 입력하고 출력하는 프로시저 - 실제로 위 테이블은 존재하지 않음 DELIMITER $$ CREATE PROCEDURE pbj_db.exception_test() BEGIN INSERT INTO pbj_db.abcdefghijklmnop(datetime) ( SELECT NOW() ); END $$ DELIMITER ; 2) 에러 확인 call pbj_db.exception_test(); - 결과(1146 에러 발생) 3) 프로시저 삭제 DROP procedure pbj_db.exception_test; 4) 예외처리한 프로시저 생성..
 [통계학] python을 통한 모평균의 신뢰구간 계산
[통계학] python을 통한 모평균의 신뢰구간 계산
0. 목표 - python을 통한 모평균의 신뢰구간 계산 1. 실습 1) library 호출 import random import matplotlib.pyplot as plt import pandas as pd import numpy as np 2) 모집단 생성 - 0과 1이 나오는 랜덤 게임을 만들고 10번을 던져 더한 값을 10000번 반복하여 저장 def game(inp): try_result = [] for i in range(inp): try_result.append(random.randint(0, 1)) result = sum(try_result) return result def game_result(inp): result = [] for i in range(inp): result.append..
 [PYTHON] dataprep을 통한 EDA
[PYTHON] dataprep을 통한 EDA
0. 목표 - dataprep 을 통한 EDA 1. 설치 pip install dataprep 2. 실습 1) library 호출 from dataprep.eda import * import pandas as pd 2) 데이터 읽기 - titanic 데이터 사용 train_df = pd.read_csv('/Users/pbj0812/Desktop/titanic/train.csv') 3) 전체 데이터에 대한 plot plot(train_df) - 위의 Show Stats Info 클릭시 요약 테이블 정보 호출 4) 데이터 카테고리화 및 재 시각화 - Survived와 Pclass는 숫자가 아닌 카테고리이기 때문에 object로 변환 for col in ['Survived', 'Pclass']: train_d..
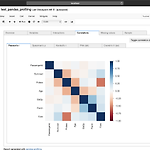 [PYTHON] pandas_profiling을 통한 EDA
[PYTHON] pandas_profiling을 통한 EDA
0. 목표 - pandas_profiling을 통한 jupyter notebook 에서의 EDA 1. 설치 pip install pandas-profiling 2. 실습 1) library 호출 import numpy as np import pandas as pd from pandas_profiling import ProfileReport 2) 데이터 호출 - 타이타닉 데이터 사용 df = pd.read_csv("/Users/pbj0812/Desktop/titanic/train.csv") 3) 보고서 생성 profile = ProfileReport(df, title='Pandas Profiling Report', explorative=True) 4) 보여주기 profile.to_widgets() - 결과..
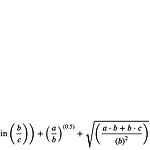 [PYTHON] handcalcs 라이브러리를 통한 수식 작성
[PYTHON] handcalcs 라이브러리를 통한 수식 작성
0. 목표 - handcalcs 라이브러리를 통한 python으로 수식 작성(Jupyter notebook) 1. 설치 pip install handcalcs 2. 실습 1) library 호출 import handcalcs.render from math import pi, sqrt, sin, asin 2) 기본 사용법 - 셀의 첫 줄에 %%render 입력 이후 적으면 수식 작성 %%render a = 2 b = 3 c = 2*a + b/3 - 결과 3) Parameters - 옵션 유무에 따라 3 열로 나눠 쓰느냐 행마다 쓰냐의 차이 %%render # Parameters a = 1 b = 2 c = 3 d = 4 %%render a = 1 b = 2 c = 3 d = 4 4) Long, Short ..
 [통계학] python으로 F 분포 그래프 그리기
[통계학] python으로 F 분포 그래프 그리기
0. 목표 - python으로 F 분포 그래프 그리기 - 독립된 두 카이제곱 분포를 따르는 확률변수 비의 분포, 등분산검정과 분산분석 등에 주로 이용 - F 값 = (카이제곱 / 자유도) / (카이제곱 / 자유도) 1. 실습 1) library 호출 import numpy as np import pandas as pd import matplotlib.pyplot as plt 2) 카이제곱 리스트 연산 함수 - 1000번 시행 def normal(inp): result = [] for i in range(1,1001): tmp = np.random.normal(size = inp) dummy = 0 for i in range(inp): tmp2 = tmp[i] ** 2 dummy += tmp2 result..
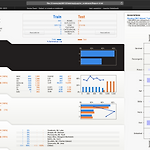 [PYTHON] sweetviz를 통한 EDA
[PYTHON] sweetviz를 통한 EDA
0. 목표 - sweetviz 를 통한 EDA 1. 실습 1) 설치 pip install sweetviz 2) library 호출 import sweetviz import pandas as pd 3) 데이터 불러오기 - 데이터는 타이타닉 데이터 사용 train = pd.read_csv("/Users/pbj0812/Desktop/titanic/train.csv") test = pd.read_csv("/Users/pbj0812/Desktop/titanic/test.csv") 4) 리포트 생성 my_report = sweetviz.compare([train, "Train"], [test, "Test"], "Survived") 5) 리포트 표출 - html 형식으로 표출 my_report.show_html("R..
 [통계학] python을 통한 자유도에 따른 카이제곱 분포 그리기
[통계학] python을 통한 자유도에 따른 카이제곱 분포 그리기
0. 목표 - python을 통한 자유도에 따른 카이제곱 분포 그리기 - 카이제곱 분포는 정규분포를 따르는 여러 데이터를 한꺼번에 취급할 수 있어, 분산분석에 이용가능 1. 실습 1) library 호출 import numpy as np import pandas as pd import matplotlib.pyplot as plt 2) 카이제곱 리스트 생성 - np.normal.random을 통해 정규분포의 무작위 값 획득 - 1000번을 돌려 각 값에 대한 제곱값을 획득 def normal(inp): result = [] for i in range(1,1001): tmp = np.random.normal(size = inp) dummy = 0 for i in range(inp): tmp2 = tmp[i]..