
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 매틀랩
- 서평단
- Python
- matplotlib
- 딥러닝
- MySQL
- SQL
- 텐서플로
- Ga
- MATLAB
- 통계학
- Visualization
- Tistory
- 서평
- tensorflow
- 파이썬 시각화
- 시각화
- Google Analytics
- 월간결산
- 한빛미디어서평단
- 독후감
- 파이썬
- Linux
- 블로그
- python visualization
- 리눅스
- Blog
- 한빛미디어
- 티스토리
- Pandas
- Today
- Total
목록Machine Learning (6)
pbj0812의 코딩 일기
 [Machine Learning] pycaret tutorial 따라하기
[Machine Learning] pycaret tutorial 따라하기
자세한 정보를 얻고 싶으시면 pycaret tutorial을 참조하시기 바랍니다. 0. 목표 - pycaret tutorial 따라하기 1. 실습 1) 설치 !pip install pycaret !pip install shap #interpret_model 사용시 필요 2) 데이터 불러오기 from pycaret.datasets import get_data diabetes = get_data('diabetes') 3) setup - 학습 데이터가 무엇인지, 목표 클래스는 무엇인지 설정 - 엔터 한번 입력해야 함 from pycaret.classification import * data = setup(diabetes, target = 'Class variable') 4) 모델 비교 - 예시에는 xgboos..
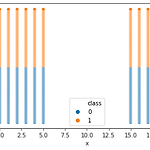 [Machine Learning] KMeans 를 통한 자동 편 가르기
[Machine Learning] KMeans 를 통한 자동 편 가르기
0. 목표 - KMeans를 통한 자동 편 가르기 1. 실습 1) 데이터 생성 import numpy as np x = np.linspace(0, 5, 6) y = np.linspace(0, 100, 101) xx, yy = np.meshgrid(x, y) xxx = np.reshape(xx, (-1, )) yyy = np.reshape(yy, (-1, )) x2 = np.linspace(15, 20, 6) y2 = np.linspace(0, 100, 101) xx2, yy2 = np.meshgrid(x2, y2) xxx2 = np.reshape(xx2, (-1, )) yyy2 = np.reshape(yy2, (-1, )) import pandas as pd df = pd.DataFrame({'x' : ..
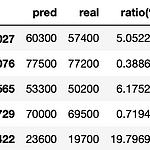 [Machine Learning] RandomForest 를 이용한 집값 예측
[Machine Learning] RandomForest 를 이용한 집값 예측
0. 목표 - RandomForest 를 이용한 집값 예측 1. 실습 1) 데이터 생성 - randomGenerator : 데이터 길이, 최소값, 최대값을 입력하면 주어진 길이만큼 최소값, 최대값 범위에서 랜덤한 정수로 채워줌 - root, yard, bathroom, livingroom, room 변수 생성 - price에는 각 변수에 원하는 값을 매겨서 합산(정확한 가중치 적용) import pandas as pd import random def randomGenerator(num_len, num_min, num_max): result = [] for i in range(num_len): result.append(random.randint(num_min, num_max)) return result r..
 [kaggle] Intermediate Machine Learning 수료 과정
[kaggle] Intermediate Machine Learning 수료 과정
0. 목차 및 내용 1) Introduction - 이전 과정(Intro to Machine Learning) 에 대한 복습 및 앞으로의 과정 소개 2) Missing Values - 결측값에 관한 처리 방안(sklearn.impute 의 SimpleImputer 소개) (1) 칼럼 삭제 (2) 다른 숫자로 채우기 (3) 라벨링? 을 통한 표기 3) Categorical Variables - 카테고리 항목에 대한 라벨링 방안 및 학습 과정 소개(sklearn.preprocessing 의 LabelEncoder, OneHotEncoder 소개) (1) 칼럼 삭제 (2) 다른 숫자로 라벨링 (3) 원-핫 인코딩 4) Pipelines - 데이터 전처리부터 모델구성까지 도와주는 pipeline 에 대한 소개 ..
 [kaggle] Intro to Machine Learning 수료 과정
[kaggle] Intro to Machine Learning 수료 과정
0. 목차 - Machine Learning 입문 과정으로 Pandas 로 데이터를 읽고 전처리 하는 과정부터 시작하여, Decision Tree, Random Forest 등을 통해 모델을 만들고 학습하는 과정, 그리고 평가하는 방법을 배울 수 있음. - kaggle 에서 제공하는 내부 jupyter notebook 으로 진행하기에 1) How Models Work 2) Basic Data Exploration 3) Your First Machine Learning Model 4) Model Validation 5) Underfitting and Overfitting 6) Random Forest 7) Machine Learning Competitions 1. 최종 코드 # Code you have p..
 [kaggle] titanic 문제 풀기
[kaggle] titanic 문제 풀기
0. 목표 - titanic - 데이터 설명 1. 실습 1) 라이브러리 호출 - 결과 : ['test.csv', 'train.csv'] import numpy as np import pandas as pd import os print(os.listdir("../input")) 2) 파일 읽기 train_df = pd.read_csv('../input/train.csv') test_df = pd.read_csv('../input/test.csv') 3) 데이터 확인 (1) train_df train_df.head() (2) test_df - train에서 Survived만 제외된 형태 test_df.head() 4) 자료구조 확인 - 12개 칼럼, 891개 데이터로 이루어져 있으며 Age와 Cabin, E..