
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 텐서플로
- 독후감
- 매틀랩
- 파이썬 시각화
- 통계학
- MySQL
- Ga
- Python
- Tistory
- 서평
- 파이썬
- MATLAB
- 한빛미디어서평단
- Blog
- tensorflow
- SQL
- 딥러닝
- Google Analytics
- Pandas
- 리눅스
- 한빛미디어
- matplotlib
- 시각화
- 블로그
- 월간결산
- Linux
- 티스토리
- python visualization
- 서평단
- Visualization
- Today
- Total
pbj0812의 코딩 일기
[Machine Learning] RandomForest 를 이용한 집값 예측 본문
[Machine Learning] RandomForest 를 이용한 집값 예측
pbj0812 2021. 5. 5. 08:320. 목표
- RandomForest 를 이용한 집값 예측
1. 실습
1) 데이터 생성
- randomGenerator : 데이터 길이, 최소값, 최대값을 입력하면 주어진 길이만큼 최소값, 최대값 범위에서 랜덤한 정수로 채워줌
- root, yard, bathroom, livingroom, room 변수 생성
- price에는 각 변수에 원하는 값을 매겨서 합산(정확한 가중치 적용)
import pandas as pd
import random
def randomGenerator(num_len, num_min, num_max):
result = []
for i in range(num_len):
result.append(random.randint(num_min, num_max))
return result
roof = randomGenerator(10000, 0, 1)
yard = randomGenerator(10000, 0, 1000)
bathroom = randomGenerator(10000, 1, 5)
livingroom = randomGenerator(10000, 0, 3)
room = randomGenerator(10000, 1, 20)
df = pd.DataFrame({'roof' : roof, 'yard' : yard, 'bathroom' : bathroom, 'livingroom' : livingroom, 'room' : room})
df['price'] = df['roof'] * 1000 + df['yard'] * 100 + df['bathroom'] * 500 + df['livingroom'] * 800 + df['room'] * 300
df.head()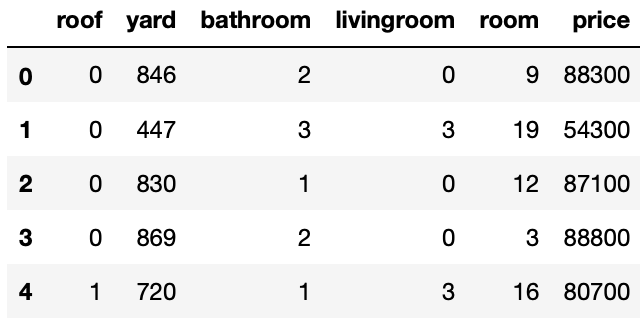
2) train, test 데이터 분류
- price 를 y로 놓고 7:3 분류
x = df[['roof', 'yard', 'bathroom', 'livingroom', 'room']]
y = df['price']
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)3) 모델 학습
- RandomForest 사용
- n_estimators : 생성할 트리 개수
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators = 100)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
result = pd.DataFrame({'pred' : y_pred, 'real' : y_test})
result.head()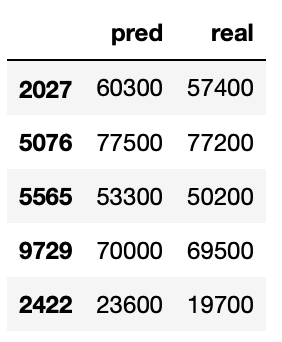
4) 모델 평가
- RMSE를 하면 터져버릴 거 같아서 MAE 사용
- MAE score: 2117.9333333333334
- 얼마나 좋은건지 잘 모르겠음
from sklearn.metrics import mean_absolute_error
print('MAE score:', mean_absolute_error(y_test, y_pred))5) 모델 평가2
- 오차를 실제값의 퍼센트로 나타냄
result['ratio(%)'] = abs((result['pred'] - result['real']) / result['real']) * 100
result.head()
- 그것들의 평균
- 5.3810274575466135(%)
import numpy as np
mean_ratio = np.mean(result['ratio(%)'])
print(mean_ratio)6) n_estimators 의 차이에 따른 결과 비교
- 여러번 돌려보았을 때 오히려 1이 가장 작게 나올때도 있긴 하지만... 일반적으로 n_estimators 가 클수록 값이 좋음
num = [1, 10, 100, 200]
for i in num:
model = RandomForestClassifier(n_estimators = i)
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
percent = abs((y_pred - y_test) / y_test) * 100
print(np.mean(percent))
2. 참고
- [Python 분류] 랜덤포레스트(Random Forest) iris 데이터 예측 :: 마이자몽
- 머신러닝 - 5. 랜덤 포레스트(Random Forest)
- sklearn.metrics.mean_squared_error
- [Kaggle] 보스턴 주택 가격 예측(House Prices: Advanced Regression Techniques)
'인공지능 & 머신러닝 > Machine Learning' 카테고리의 다른 글
| [Machine Learning] pycaret tutorial 따라하기 (0) | 2021.05.12 |
|---|---|
| [Machine Learning] KMeans 를 통한 자동 편 가르기 (0) | 2021.05.11 |
| [Machine Learning] KNN 으로 편가르기 (0) | 2021.05.07 |
| [Machine Learning] XGBoost 를 이용한 집값 예측 (0) | 2021.05.06 |



