
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 파이썬
- MySQL
- 서평단
- 매틀랩
- Visualization
- 파이썬 시각화
- 월간결산
- 시각화
- Pandas
- 서평
- tensorflow
- 독후감
- 리눅스
- Python
- matplotlib
- 딥러닝
- SQL
- 티스토리
- 한빛미디어서평단
- Google Analytics
- Ga
- 통계학
- Tistory
- 텐서플로
- 한빛미디어
- MATLAB
- 블로그
- python visualization
- Blog
- Linux
Archives
- Today
- Total
pbj0812의 코딩 일기
[Machine Learning] KMeans 를 통한 자동 편 가르기 본문
0. 목표
- KMeans를 통한 자동 편 가르기
1. 실습
1) 데이터 생성
import numpy as np
x = np.linspace(0, 5, 6)
y = np.linspace(0, 100, 101)
xx, yy = np.meshgrid(x, y)
xxx = np.reshape(xx, (-1, ))
yyy = np.reshape(yy, (-1, ))
x2 = np.linspace(15, 20, 6)
y2 = np.linspace(0, 100, 101)
xx2, yy2 = np.meshgrid(x2, y2)
xxx2 = np.reshape(xx2, (-1, ))
yyy2 = np.reshape(yy2, (-1, ))
import pandas as pd
df = pd.DataFrame({'x' : xxx, 'y' : yyy})
df2 = pd.DataFrame({'x' : xxx2, 'y' : yyy2})
df3 = pd.concat([df, df2], axis = 0)
df3.head()
2) 데이터 시각화
import seaborn as sns
sns.scatterplot(data = df3, x = "x", y = "y")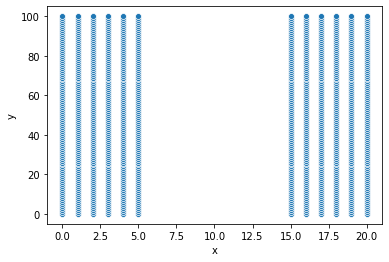
3) 학습
- 두 개의 군집으로 분류
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=0).fit(df3)4) 결과 시각화
df3['class'] = kmeans.labels_
sns.scatterplot(data = df3, x = "x", y = "y", hue = 'class', legend = "full")
5) 임의 데이터로 분류
- 결과 : 1
kmeans.predict([[10, 80]])2. 참고
'인공지능 & 머신러닝 > Machine Learning' 카테고리의 다른 글
| [Machine Learning] pycaret tutorial 따라하기 (0) | 2021.05.12 |
|---|---|
| [Machine Learning] KNN 으로 편가르기 (0) | 2021.05.07 |
| [Machine Learning] XGBoost 를 이용한 집값 예측 (0) | 2021.05.06 |
| [Machine Learning] RandomForest 를 이용한 집값 예측 (2) | 2021.05.05 |
'인공지능 & 머신러닝/Machine Learning' Related Articles
more




Comments