
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 파이썬
- 매틀랩
- matplotlib
- 파이썬 시각화
- 한빛미디어
- SQL
- Python
- 독후감
- Tistory
- 블로그
- python visualization
- Blog
- Pandas
- Visualization
- tensorflow
- Ga
- 티스토리
- 딥러닝
- MySQL
- MATLAB
- 시각화
- Linux
- Google Analytics
- 통계학
- 서평
- 리눅스
- 한빛미디어서평단
- 텐서플로
- 서평단
- 월간결산
- Today
- Total
목록분류 전체보기 (596)
pbj0812의 코딩 일기
 [독후감] UX/UI 디자이너를 위한 실무 피그마
[독후감] UX/UI 디자이너를 위한 실무 피그마
"한빛미디어 활동을 위해서 책을 제공받아 작성된 서평입니다." 0. 도서정보 1) 도서명 : UX/UI 디자이너를 위한 실무 피그마 2) 저자 : 클레어 정 3) 링크 1. 서평 - 본업이 디자이너는 아니지만... 협업을 하기 위해 피그마로 제작된 결과물을 매일 보고 있기에 피그마에 어떤 기능들이 있는지 확인하기 위하여 해당도서를 보게 되었다. 해당 도서는 2부로 이루어져 있으며 먼저, 이 책의 특별한 구성이라고 하면 1부에 있는 피그마를 활용한 (기획자, 개발자)의 하루로 기획자 및 개발자들이 피그마를 통해 하루 일과가 어떻게 흘러가는지 가정을 통해 풀어나갔다. 만약, 현재 기획자나 개발자가 아니라면 해당 페이지를 읽고 상상한 다음 자신의 목표에 맞게 집중할 파트를 확인해 보는 것도 좋을 것 같다. 그..

0. 목표 - 산술평균, 기하평균, 조화평균 python, sql 로 구현하기 1. python 으로 구현하기 1) 산술평균 : 3.0 - 흔히 아는 평균, 상가평균 x = [1, 2, 3, 4, 5] mean_x = sum(x) / len(x) print(mean_x) 2) 기하평균 : 2.605171084697352 - 성장율, 이율의 평균을 구할 때 상용, 상승평균 x = [1, 2, 3, 4, 5] result = 1 for i in x: result = result * i mean_x2 = result ** (1/len(x)) print(mean_x2) 3) 조화평균 : 2.18978102189781 - 속도나 전기저항의 평균값 계산에 이용 - 산술평균 >= 기하평균 >= 조화평균 x = [1,..
 [통계학] python, sql 로 t-test 구현
[통계학] python, sql 로 t-test 구현
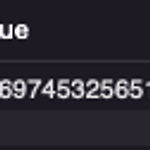
0. 목표 - python, sql 로 t-test 구현 1. 실습 1) scipy - Ttest_indResult(statistic=-3.0869745325651587, pvalue=0.031361515666731996) import numpy as np import scipy.stats x = [1, 2, 3, 4, 5] y = [4, 8, 12, 16, 20] mean_x = np.mean(x) mean_y = np.mean(y) print('x : ', mean_x) print('y : ', mean_y) scipy.stats.ttest_ind(x, y, equal_var=False) 2) 그냥 파이썬 - -3.0869745325651587 import numpy as np import math ..
 [독후감] 혼자 공부하는 데이터 분석 with 파이썬
[독후감] 혼자 공부하는 데이터 분석 with 파이썬
"한빛미디어 활동을 위해서 책을 제공받아 작성된 서평입니다." 1. 도서 정보 - 도서명 : 혼자 공부하는 데이터 분석 with 파이썬 - 저자 : 박해선 - 링크 2. 후기 - 제목처럼 파이썬을 통한 데이터 분석 입문용으로는 추천할 수 있다. 기본 환경 세팅인 코랩 설치를 시작으로 csv, api 를 통한 데이터 수집 및 크롤링을 통한 데이터 수집 방법도 기술되어 있다. 데이터 분석 방법으로는 기본적인 판다스 라이브러리 사용 및 기초 통계(중앙값, 표준편차), 간단한 시각화 방법도 기술되어 있다. 그렇기에 데이터 분석에 대한 절차를 알아보기에는 좋은 책이라고 할 수 있으나... 넓은 분야를 다루다보니 깊이가 깊을수는 없기에 이미 데이터 분석을 할 수 있으신 분들께는 추천드리지 않으며 또한, 파이썬도 모..
 [SQL] RECURSIVE CTE 구문을 통한 길찾기
[SQL] RECURSIVE CTE 구문을 통한 길찾기
0. 목표 - RECURSIVE CTE 구문을 통한 길찾기 1. 실습 1) 테이블 생성 CREATE TABLE sql_study.recursive_test ( city_from varchar(10), city_to varchar(10) ); 2) 데이터 삽입 INSERT INTO sql_study.recursive_test(city_from, city_to) VALUES('서울', '대전'); INSERT INTO sql_study.recursive_test(city_from, city_to) VALUES('대전', '대구'); INSERT INTO sql_study.recursive_test(city_from, city_to) VALUES('대구', '부산'); 3) 쿼리 작성 - UNION ALL 위..
 [SQL] 복수개의 json 정보들을 풀어헤치기
[SQL] 복수개의 json 정보들을 풀어헤치기
0. 목표 - 복수개의 json 정보들을 풀어헤치기 1. 실습 1) 테이블 생성 CREATE TABLE sql_study.json_test ( id int, json_field longtext ); 2) 데이터 삽입 - id 가 1 인 것은 json 두개가 결합되어 있고, 3 은 세개가 결합되어 있음 INSERT INTO sql_study.json_test(id, json_field) VALUES(1, '[{"a" : "abc", "b" : "bbc"}, {"a" : "abc2", "b" : "bbc2"}]'); INSERT INTO sql_study.json_test(id, json_field) VALUES(2, NULL); INSERT INTO sql_study.json_test(id, json_fi..
 [통계학] z-score 를 python, MySQL 로 구현하기
[통계학] z-score 를 python, MySQL 로 구현하기
0. 목표 - z-score 를 python, MySQL 로 구현하기 1. 이론 - 데이터의 평균을 0.0 으로 표준편차를 1.0 으로 만드는 기법 2. 구현 1) scipy 로 구현 from scipy import stats x = [i for i in range(1, 10)] z_score = stats.zscore(x) print(z_score) 2) 그냥 python 으로 구현 import math x = [i for i in range(1, 10)] len_x = len(x) # 길이 x_mean = sum(x) / len_x # 평균 x_var = 0 for i in x: x_var += (i - x_mean) ** 2 x_var = x_var / len_x # 분산 x_std = math.s..
 [빅쿼리] 콘솔에서 테이블 만들기
[빅쿼리] 콘솔에서 테이블 만들기
0. 접속 - bigquery console 검색해서 들어가거나... - 링크 클릭 1. 클릭 - 콘솔로 이동 클릭(처음 이라면 무료로 이용해보기 클릭해서 카드 정보 넣어야 함, 카드 정보 넣어도 돈은 나가지 않음.) 2. 화면 - 좌측에 보이는 것들이 테이블 관련 모음으로 프로젝트 > 데이터 세트 > 테이블의 구조로 이루어져 있으며, 가운데 부분이 쿼리를 칠 수 있는 부분 3. 데이터 세트 만들기1 - 점 세개 찍힌 버튼(케밥 버튼) 클릭하여 데이터 세트 만들기 클릭(사진에서는 data-to-insights 버튼을 클릭했는데, 추가 권한이 없어 개인 프로젝트에다가 데이터 세트 구축) 4. 데이터 세트 만들기2 - 적당히 채워 넣는다.(마찬가지로 여기서는 프로젝트 ID 가 data-to-insights ..
 [PYTHON] PyScript 로 그림 그리기
[PYTHON] PyScript 로 그림 그리기
0. 작업 준비 - 파일 확장자는 html 로 한다. 1. 코드 작성 - link, script 는 복붙하면 된다. - py-config 에는 불러올 라이브러리를 적는다. - py-script 에 본문을 적는다. - 마지막에 쓴 display 함수를 통해 그릴 곳을 지정한다. - id = graph-area 확인 packages = ["matplotlib", "numpy"] import numpy as np import matplotlib.pyplot as plt from matplotlib.patches import Ellipse, Polygon x = -1 y = abs(x) * np.tan(1/3 * np.pi) y_1 = 1/3 * y y_2 = 2/3 * y data = [1, 1, 2] n =..