
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 매틀랩
- 파이썬
- 서평단
- 텐서플로
- Pandas
- 티스토리
- 한빛미디어서평단
- Python
- 딥러닝
- Blog
- 한빛미디어
- python visualization
- 블로그
- 파이썬 시각화
- Tistory
- 독후감
- SQL
- tensorflow
- 서평
- Ga
- 월간결산
- MySQL
- Linux
- Google Analytics
- 리눅스
- 통계학
- MATLAB
- matplotlib
- Visualization
- 시각화
- Today
- Total
목록Science (49)
pbj0812의 코딩 일기
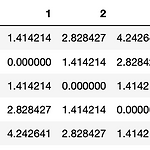 [수학] python으로 유클리드 거리 계산하기
[수학] python으로 유클리드 거리 계산하기
0. 목표 - python으로 유클리드 거리 계산하기 1. 기본 이론 - 링크 2. 실습 1) library 호출 import numpy as np import pandas as pd 2) 제곱근 함수 제작 - 에러 발생시(입력값이 0인 경우) 결과값이 0으로 출력 def sqrt(inp): result = inp/2 for i in range(30): try: result = (result + (inp / result)) / 2 except: result = 0 return result 3) 유클리드거리 계산 함수 제작 - 이중 for문을 통하여 모든 리스트 값이 한번씩 마주치면서 유클리드 거리 계산을 한 뒤 데이터 프레임의 형태로 출력 def euclidean(inp): result = [] len_..
0. 목표 - 가우스 조던 소거법을 통한 연립방정식 계산(python 사용) - 아래식의 해 도출 y -3z = -5 2x + 3y -z = 7 4x + 5y - 2z = 10 1. 이론 - 예제 링크 2. 실습 1) library 호출 import numpy as np import copy 2) 데이터 생성 - x, y, z 순서대로 a 행렬 생성 * .0을 붙이지 않고 정수 형태로 만들경우 뒷 부분의 나눗셈 부분에서 정수로 떨어짐 a = np.array([[0.0, 1.0, -3.0], [2.0, 3.0, -1.0], [4.0, 5.0, -2.0]]) b = np.array([[-5.0], [7.0], [10.0]]) 3) 확인용 함수 def check(a, b): print(a) print('===..
0. 목표 - python을 이용한 U 값 계산 - U 값 : 두 집단을 순위 데이터로 변환하여 분포가 겹치는 정도를 나타내는 통계량 1. 방법 1) 데이터를 양 집단을 합친 순위로 변환 2) 양 집단을 합쳐서 작은순으로 순서를 붙임 3) A 집단보다 작은 B 직단의 개수를 계산하고 그 값을 합산한 값이 U 값 2. 구현 1) 두 집단(데이터) 생성 a = [10.2, 8.3, 5.1, 3.4] b = [90.0, 10.2, 7.7, 6.8, 4.0] 2) 두 집단(데이터)을 하나로 합침 - [10.2, 8.3, 5.1, 3.4, 90.0, 10.2, 7.7, 6.8, 4.0] total = a + b print(total) 3) 순서 정렬 - [3.4, 4.0, 5.1, 6.8, 7.7, 8.3, 10..
 [통계학] spicy 패키지를 이용한 동전 던지기(베이지안)
[통계학] spicy 패키지를 이용한 동전 던지기(베이지안)
0. 목표 - scipy 패키지를 이용한 동전 던지기 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import matplotlib from IPython.core.pylabtools import figsize from matplotlib import rc import scipy.stats as stats 2) 함수 제작 - stats.beta : 베타분포 객체 생성(링크) - stats.bernoulli.rvs(0.5, size = inp[-1]) : 베르누이 시뮬레이션(확률 0.5로 계산, inp[-1]로 지정한 것은 리스트(숫자가 커지는 형태)로 받아서 돌릴때 가장 마지막 값(가장 긴 값)을 근거해서 그림을 그릴 것이기..
 [통계학] 몬테 카를로 방법을 통한 원의 넓이 계산(python)
[통계학] 몬테 카를로 방법을 통한 원의 넓이 계산(python)
0. 목표 - 몬테 카를로 방법을 통한 원의 넓이 계산 1. 실습 1) library 호출 import random import matplotlib.pyplot as plt 2) 인풋 데이터 제작 함수 - x와 y가 -1 ~ 1 사이의 랜덤한 실수 생성 - x**2 + y**2 가 1보다 작을 경우 원의 넓이에 포함되게 리스트에 넣어줌 def monte(inp): circle = 0 non_circle = 0 circle_x = [] circle_y = [] non_circle_x = [] non_circle_y = [] for i in range(inp): x = random.uniform(-1, 1) y = random.uniform(-1, 1) if (x**2) + (y**2)
 [통계학] python을 이용한 블로그 방문자수 회귀선 그리기
[통계학] python을 이용한 블로그 방문자수 회귀선 그리기
* 주의 : 이 데이터는 회귀를 사용하기에는 좋은 데이터가 아닙니다!!! 0. 목표 - python을 이용한 내 블로그 방문자 수 회귀선 그리기 - Y = a + bX (링크) 1. 실습 1) library 호출 import matplotlib.pyplot as plt 2) 데이터 생성 - y : 블로그를 다시 쓰기 시작한 2019년 2월 부터의 방문자수를 사용 - x : 2019년 2월을 1로 두고 1씩 증가하는 형태 y = [98, 221, 221, 419, 440, 451, 531, 523, 699, 612, 977, 1002, 1263, 1531, 2174, 3320, 3758, 5161] x = [i for i in range(1, len(y) + 1)] 3) 데이터 확인 plt.bar(x, y..
0. 목표 - python을 이용한 부트스트랩 구현 1. 이론 1) 샘플 값을 하나 뽑아서 기록하고 제자리에 놓는다. 2) n번 반복한다. 3) 재표본추출된 값의 평균을 길록한다. 4) 1~3단계를 R번 반복한다. 5) R개의 결과를 사용하여 (1) 표준편차 계산 (2) 히스토그램 or 상자그림 (3) 신뢰구간 찾기 2. 실습 1) library 호출 import numpy as np 2) 평균 def mean(inp): result = 0 len_inp = len(inp) for i in inp: result += i result = result / len_inp return result 3) 모수생성 - 정규 분포를 따르는 백만개의 수 생성 mom = list(np.random.normal(size ..
 [통계학] python을 통한 모평균의 신뢰구간 계산
[통계학] python을 통한 모평균의 신뢰구간 계산
0. 목표 - python을 통한 모평균의 신뢰구간 계산 1. 실습 1) library 호출 import random import matplotlib.pyplot as plt import pandas as pd import numpy as np 2) 모집단 생성 - 0과 1이 나오는 랜덤 게임을 만들고 10번을 던져 더한 값을 10000번 반복하여 저장 def game(inp): try_result = [] for i in range(inp): try_result.append(random.randint(0, 1)) result = sum(try_result) return result def game_result(inp): result = [] for i in range(inp): result.append..
 [통계학] python으로 F 분포 그래프 그리기
[통계학] python으로 F 분포 그래프 그리기
0. 목표 - python으로 F 분포 그래프 그리기 - 독립된 두 카이제곱 분포를 따르는 확률변수 비의 분포, 등분산검정과 분산분석 등에 주로 이용 - F 값 = (카이제곱 / 자유도) / (카이제곱 / 자유도) 1. 실습 1) library 호출 import numpy as np import pandas as pd import matplotlib.pyplot as plt 2) 카이제곱 리스트 연산 함수 - 1000번 시행 def normal(inp): result = [] for i in range(1,1001): tmp = np.random.normal(size = inp) dummy = 0 for i in range(inp): tmp2 = tmp[i] ** 2 dummy += tmp2 result..
 [통계학] python을 통한 자유도에 따른 카이제곱 분포 그리기
[통계학] python을 통한 자유도에 따른 카이제곱 분포 그리기
0. 목표 - python을 통한 자유도에 따른 카이제곱 분포 그리기 - 카이제곱 분포는 정규분포를 따르는 여러 데이터를 한꺼번에 취급할 수 있어, 분산분석에 이용가능 1. 실습 1) library 호출 import numpy as np import pandas as pd import matplotlib.pyplot as plt 2) 카이제곱 리스트 생성 - np.normal.random을 통해 정규분포의 무작위 값 획득 - 1000번을 돌려 각 값에 대한 제곱값을 획득 def normal(inp): result = [] for i in range(1,1001): tmp = np.random.normal(size = inp) dummy = 0 for i in range(inp): tmp2 = tmp[i]..