
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 한빛미디어서평단
- Python
- 서평
- Blog
- matplotlib
- 월간결산
- 텐서플로
- 시각화
- Visualization
- 딥러닝
- Linux
- 블로그
- SQL
- Google Analytics
- 독후감
- Tistory
- 한빛미디어
- 파이썬 시각화
- Ga
- 매틀랩
- 리눅스
- Pandas
- 통계학
- MySQL
- MATLAB
- 티스토리
- 서평단
- tensorflow
- python visualization
- 파이썬
- Today
- Total
목록kmeans (2)
pbj0812의 코딩 일기
 [Machine Learning] KMeans 를 통한 자동 편 가르기
[Machine Learning] KMeans 를 통한 자동 편 가르기
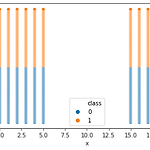
0. 목표 - KMeans를 통한 자동 편 가르기 1. 실습 1) 데이터 생성 import numpy as np x = np.linspace(0, 5, 6) y = np.linspace(0, 100, 101) xx, yy = np.meshgrid(x, y) xxx = np.reshape(xx, (-1, )) yyy = np.reshape(yy, (-1, )) x2 = np.linspace(15, 20, 6) y2 = np.linspace(0, 100, 101) xx2, yy2 = np.meshgrid(x2, y2) xxx2 = np.reshape(xx2, (-1, )) yyy2 = np.reshape(yy2, (-1, )) import pandas as pd df = pd.DataFrame({'x' : ..
 [통계] k-means 설명 / 코드 분석
[통계] k-means 설명 / 코드 분석
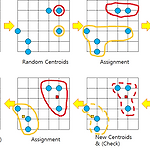
1. 정의 k-평균 알고리즘(K-means algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 이 알고리즘은 자율 학습의 일종으로, 레이블이 달려 있지 않은 입력 데이터에 레이블을 달아주는 역할을 수행한다. 이 알고리즘은 EM 알고리즘을 이용한 클러스터링과 비슷한 구조를 가지고 있다. 2. 절차 1) 초기 (군집의) 중심으로 k개의 객체를 임의로 선택한다. 2) 각 자료를 가장 가까운 군집 중심에 할당한다. 3) 각 군집 내의 자료들의 평균을 계산하여 군집의 중심을 갱신(update)한다. 4) 군집 중심의 변화가 거의 없을 때(또는 최대 반복수)까지 2) 와 3) 을 반복한다. * 군집의 수(k)는 미리 정해 주어야..