
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Google Analytics
- python visualization
- Blog
- 파이썬
- tensorflow
- Pandas
- 매틀랩
- Python
- 리눅스
- 월간결산
- MATLAB
- 파이썬 시각화
- 한빛미디어서평단
- Linux
- 딥러닝
- SQL
- 블로그
- 서평단
- 한빛미디어
- 티스토리
- MySQL
- Tistory
- 시각화
- 서평
- 텐서플로
- matplotlib
- 통계학
- 독후감
- Visualization
- Ga
- Today
- Total
pbj0812의 코딩 일기
[통계] k-means 설명 / 코드 분석 본문
1. 정의
k-평균 알고리즘(K-means algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 이 알고리즘은 자율 학습의 일종으로, 레이블이 달려 있지 않은 입력 데이터에 레이블을 달아주는 역할을 수행한다. 이 알고리즘은 EM 알고리즘을 이용한 클러스터링과 비슷한 구조를 가지고 있다.
2. 절차
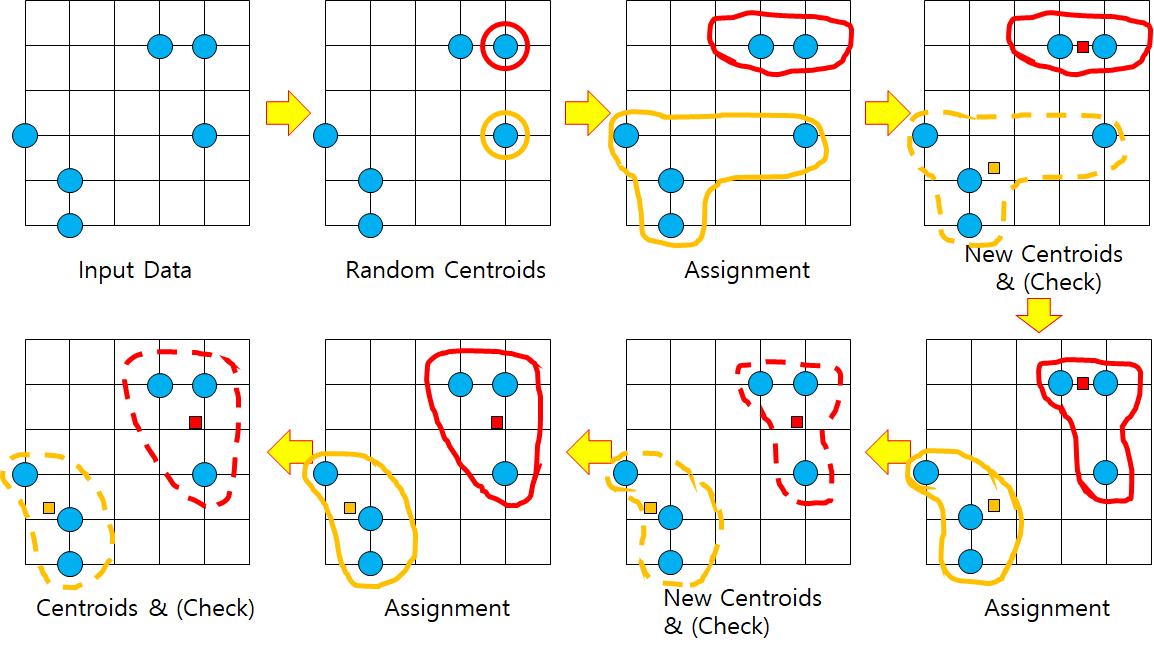
1) 초기 (군집의) 중심으로 k개의 객체를 임의로 선택한다.
2) 각 자료를 가장 가까운 군집 중심에 할당한다.
3) 각 군집 내의 자료들의 평균을 계산하여 군집의 중심을 갱신(update)한다.
4) 군집 중심의 변화가 거의 없을 때(또는 최대 반복수)까지 2) 와 3) 을 반복한다.
* 군집의 수(k)는 미리 정해 주어야 하나, 서로 멀리 떨어져 있는 것이 바람직하다.
3. 주의사항

- 위와 같이 이상값이 존재할 경우 민감하게 반응한다.
- 이에 대처하기 위해서는 이상값을 미리 제거하거나 k-medoids 군집을 사용할 수 있다.
4. 코드
* 코드는 조대협님의 코드를 토대로 수정 및 작성 하였습니다.
from sklearn import datasets
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns- kmeans를 위한 sklearn 사용한다.
iris = datasets.load_iris()- 데이터는 iris 데이터(3종류의 붓꽃 정보 포함)를 사용한다.
data = pd.DataFrame(iris.data)
data.columns=['Sepal length','Sepal width','Petal length','Petal width']
- 데이터를 DataFrame 형식으로 바꿔준다.
feature = data[ ['Sepal length','Sepal width']]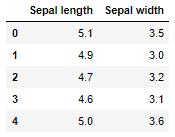
- 꽃받침의 가로, 세로 길이를 feature로 지정한다.
model = KMeans(n_clusters=3,algorithm='auto')
model.fit(feature)
predict = pd.DataFrame(model.predict(feature))
predict.columns=['predict']- 모델을 생성 및 적용(fit)한다.
- 우리는 iris 데이터가 3종류의 꽃의 정보를 담고 있는 데이터임을 알고 있기에 n_cluster를 3으로 지정한다.
- algorithm='auto'는 기본 값으로 상황에 따라 'full'이나 'elkan' 옵션으로 적용하며 이는 데이터에 따라 다르다.(참고)

- 결과
r = pd.concat([feature,predict],axis=1)- 기존 데이터와 예측값 결합
plt.scatter(r['Sepal length'],r['Sepal width'],c=r['predict'],alpha=0.5)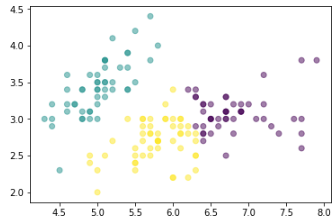
- 분류 결과
centers = pd.DataFrame(model.cluster_centers_,columns=['Sepal length','Sepal width'])
center_x = centers['Sepal length']
center_y = centers['Sepal width']
plt.scatter(center_x,center_y,s=50,marker='D',c='r')
- 중심 찾기
plt.scatter(r['Sepal length'],r['Sepal width'],c=r['predict'],alpha=0.5)
plt.scatter(center_x,center_y,s=50,marker='D',c='r')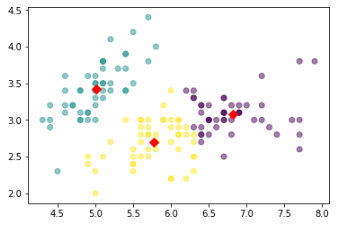
- 같이 그리기
5. 참고문헌
1) 데이터 분석 전문가 가이드(한국 데이터 진흥원)
2) 위키피디아
3) 조대협님 블로그
'Machine Learning Lecture > 잡지식' 카테고리의 다른 글
| [Docker] 설치, 다운로드, 실행, jupyter notebook 연동, 삭제, 기타 등등 (0) | 2019.04.29 |
|---|---|
| [머신러닝] MAP (0) | 2018.11.14 |
