
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- tensorflow
- 서평
- Ga
- 딥러닝
- 한빛미디어서평단
- 한빛미디어
- 파이썬 시각화
- 티스토리
- 리눅스
- Tistory
- 통계학
- 파이썬
- Linux
- Python
- 텐서플로
- 월간결산
- 매틀랩
- Visualization
- MySQL
- 서평단
- matplotlib
- python visualization
- 독후감
- Blog
- 시각화
- Google Analytics
- 블로그
- SQL
- MATLAB
- Pandas
- Today
- Total
목록통계학 (32)
pbj0812의 코딩 일기
0. 이론 - 준비한 데이터에서 복원 추출을 반복해 많은 재표본을 생성하고, 그 통계량에서 모수를 추정 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import pandas as pd import random import statistics 2) 데이터 생성 - t 분포 를 활용한 신뢰구간 : 1.03 ~ 4.97 x = [1, 2, 3, 4, 5] print('신뢰구간 : ', round(np.mean(x) - 2.78 * 0.71, 2), ' ~ ', round(np.mean(x) + 2.78 * 0.71, 2)) 3) 부트스트랩 - 5개씩 뽑아서(복원추출) 평균을 만들고 해당 데이터들을 통해 신뢰구간 구현 var = ..
0. 목표 - 산술평균, 기하평균, 조화평균 python, sql 로 구현하기 1. python 으로 구현하기 1) 산술평균 : 3.0 - 흔히 아는 평균, 상가평균 x = [1, 2, 3, 4, 5] mean_x = sum(x) / len(x) print(mean_x) 2) 기하평균 : 2.605171084697352 - 성장율, 이율의 평균을 구할 때 상용, 상승평균 x = [1, 2, 3, 4, 5] result = 1 for i in x: result = result * i mean_x2 = result ** (1/len(x)) print(mean_x2) 3) 조화평균 : 2.18978102189781 - 속도나 전기저항의 평균값 계산에 이용 - 산술평균 >= 기하평균 >= 조화평균 x = [1,..
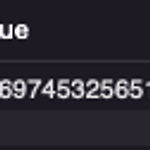 [통계학] python, sql 로 t-test 구현
[통계학] python, sql 로 t-test 구현
0. 목표 - python, sql 로 t-test 구현 1. 실습 1) scipy - Ttest_indResult(statistic=-3.0869745325651587, pvalue=0.031361515666731996) import numpy as np import scipy.stats x = [1, 2, 3, 4, 5] y = [4, 8, 12, 16, 20] mean_x = np.mean(x) mean_y = np.mean(y) print('x : ', mean_x) print('y : ', mean_y) scipy.stats.ttest_ind(x, y, equal_var=False) 2) 그냥 파이썬 - -3.0869745325651587 import numpy as np import math ..
 [통계학] z-score 를 python, MySQL 로 구현하기
[통계학] z-score 를 python, MySQL 로 구현하기
0. 목표 - z-score 를 python, MySQL 로 구현하기 1. 이론 - 데이터의 평균을 0.0 으로 표준편차를 1.0 으로 만드는 기법 2. 구현 1) scipy 로 구현 from scipy import stats x = [i for i in range(1, 10)] z_score = stats.zscore(x) print(z_score) 2) 그냥 python 으로 구현 import math x = [i for i in range(1, 10)] len_x = len(x) # 길이 x_mean = sum(x) / len_x # 평균 x_var = 0 for i in x: x_var += (i - x_mean) ** 2 x_var = x_var / len_x # 분산 x_std = math.s..
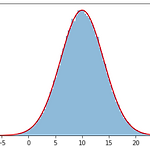 [통계학] 정규분포 그래프 그리기
[통계학] 정규분포 그래프 그리기
0. 목표 - 정규분포 그래프 그리기 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import math 2) 데이터 생성 - 평균 10, 표준편차 4, 데이터의 개수 10 만 개 data = np.random.normal(10, 4, 100000) 3) 정렬 data = sorted(data) 4) 평균 - 9.991368120797462 data_mean = sum(data) / len(data) 5) 표준편차, 분산 - 표준편차 4.013488145962863, 분산 16.10808709778442 sd = 0 for i in data: sd += (i - data_mean) ** 2 sd = math.sqrt(sd /..
 [독후감] 쉽게 배우는 통계학
[독후감] 쉽게 배우는 통계학
0. 도서 정보 - 도서명 : 쉽게 배우는 통계학 - 저자 : 구로세 나오코 - 링크 1. 후기 - 줄거리 : 길고양이가 냥이 선배(집고양이) 에게 통계학을 배우는 내용. - 진행방식 : 만화 + 줄 글 - 장점 : 만화로 되어 있어 보기가 편하다. 난이도가 입문자에게 적절하다. 고양이가 있다. 부록으로 고양이, 조사에 대한 지식을 얻을 수 있다. - 단점 : 통계학에 대한 내용보다 고양이 이야기가 더 많다.
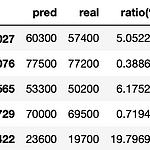 [Machine Learning] RandomForest 를 이용한 집값 예측
[Machine Learning] RandomForest 를 이용한 집값 예측
0. 목표 - RandomForest 를 이용한 집값 예측 1. 실습 1) 데이터 생성 - randomGenerator : 데이터 길이, 최소값, 최대값을 입력하면 주어진 길이만큼 최소값, 최대값 범위에서 랜덤한 정수로 채워줌 - root, yard, bathroom, livingroom, room 변수 생성 - price에는 각 변수에 원하는 값을 매겨서 합산(정확한 가중치 적용) import pandas as pd import random def randomGenerator(num_len, num_min, num_max): result = [] for i in range(num_len): result.append(random.randint(num_min, num_max)) return result r..
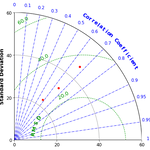 [통계학] SkillMetrics(python) 을 통한 테일러 다이어그램 그리기
[통계학] SkillMetrics(python) 을 통한 테일러 다이어그램 그리기
0. 목표 - SkillMetrics(python) 을 통한 테일러 다이어그램 그리기(예제 따라하기) 1. 설치 pip install SkillMetrics - 기본 사용법 import skill_metrics as sm sm.taylor_diagram() - 옵션(링크) 2. 데이터 다운로드 1) github.com/PeterRochford/SkillMetrics/blob/master/Examples/taylor_data.pkl 에서 다운로드 2) 데이터 확인 - 실습 PC 에서는 인코딩 문제로 아래와 같이 코드를 짜야 파일을 열 수 있음 - 해양 or 기상 관련 데이터로 보임 import pickle class Container(object): def __init__(self, pred1, pred2..
 [통계학] PYTHON 을 통한 AUPRC 구현 및 sklearn 과 비교
[통계학] PYTHON 을 통한 AUPRC 구현 및 sklearn 과 비교
0. 목표 - PYTHON 을 통한 AUPRC 구현 및 sklearn 과 비교 1. 스크래치 실습 1) library 호출 import pandas as pd import matplotlib.pyplot as plt 2) 데이터 생성 index = [i for i in range(1, 21)] label = ['p', 'p', 'n', 'p', 'p', 'p', 'n', 'n', 'p', 'n', 'p', 'n', 'p', 'n', 'n', 'n', 'p', 'n', 'p', 'n'] probability = [0.9, 0.8, 0.7, 0.6, 0.55, 0.54, 0.53, 0.52, 0.51, 0.505, 0.4, 0.39, 0.38, 0.37, 0.36, 0.35, 0.34, 0.33, 0.3, ..
 [통계학] PYTHON 을 통한 P-R 곡선 구현
[통계학] PYTHON 을 통한 P-R 곡선 구현
0. 목표 - PYTHON 을 통한 P-R 곡선 구현 1. 실습 1) library 호출 import pandas as pd import matplotlib.pyplot as plt 2) 데이터 생성 index = [i for i in range(1, 21)] label = ['p', 'p', 'n', 'p', 'p', 'p', 'n', 'n', 'p', 'n', 'p', 'n', 'p', 'n', 'n', 'n', 'p', 'n', 'p', 'n'] probability = [0.9, 0.8, 0.7, 0.6, 0.55, 0.54, 0.53, 0.52, 0.51, 0.505, 0.4, 0.39, 0.38, 0.37, 0.36, 0.35, 0.34, 0.33, 0.3, 0.1] 3) 데이터 프레임화 da..