
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- MATLAB
- 파이썬 시각화
- 서평단
- 매틀랩
- 리눅스
- 독후감
- Visualization
- matplotlib
- MySQL
- Ga
- 티스토리
- tensorflow
- Pandas
- Blog
- 텐서플로
- Python
- 월간결산
- 한빛미디어서평단
- 서평
- python visualization
- Tistory
- 시각화
- Google Analytics
- 파이썬
- 딥러닝
- SQL
- Linux
- 한빛미디어
- 통계학
- 블로그
- Today
- Total
목록분류 전체보기 (596)
pbj0812의 코딩 일기
 [Go] Package 생성, Import 하기
[Go] Package 생성, Import 하기
0. 목표 - 패키지 및 함수 생성 이후 main.go에서 import 1. 코드 작성 1) something.go - something 폴더 생성 이후 something.go 생성 - 이때, sayBye는 첫글자를 소문자, SayHello는 첫글자를 대문자로 작성 package something import "fmt" func sayBye() { fmt.Println("Bye") } func SayHello() { fmt.Println("Hello") } 2) main.go - 여기서 something.sayBye는 호출되지 않음 => 첫 글자가 소문자일 경우에는 private 함수 package main import ( "fmt" "github.com/pbj0812/learngo/something.g..
 [Go] main.go
[Go] main.go
0. main.go - 컴파일을 하기 위해선 필수 요소 (컴파일이 필요 없다면... 필요 없음) 1. Hello World! 1) package main => 작성할 패키지 이름 2) ;는 필요 없음 3) main 함수 필수 작성 package main import "fmt" //start point func main() { fmt.Println("Hello World!") } 2. 결과 3. 참고 - 쉽고 빠른 Go 시작하기(노마드코더)
 [Go] Go 설치
[Go] Go 설치
0. 목표 - Go 설치 - Go가 간결한데다가 Python에 비해 엄청 빠르다고 함 1. 설치 파일 다운로드 1) Go 공식 홈페이지에서 운영체제에 맞는 파일 다운로드(Go 홈피) 2) 설치(아래 기본 경로(C:\Go)에서 바꾸지 않도록 함) 2. 작업 환경 세팅 1) 소스 디렉토리 생성 - C:\Go\src\ 밑에 작업 폴더 생성 2) main.go 파일을 만들어서 VScode로 실행할 때 아래와 같이 Go 관련해서 뭔가 설치문구 뜨면 다 설치 - Write in Go! - Go 강의(노마드코더)
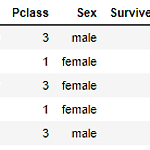 [Python] sklearn의 DecisionTree 사용 / Graphviz 설치
[Python] sklearn의 DecisionTree 사용 / Graphviz 설치
0. 목표 - sklearn 의 DecisionTree를 이용한 Titanic 문제 해결 1. DecisionTreeClassifier(참고) 1) criterion : 분류 기준(default = 'gini') 2) max_depth : decision tree의 깊이 지정 3) min_samples_split : 최소 샘플 개수 4) min_samples_leaf : 최소 분류 수 5) max_features : 최대 피쳐 수 2. 데이터셋 준비 - kaggle 타이타닉 데이터 셋 다운로드(링크에서 titanic 검색) 3. 코드 작성 1) 데이터 선정 import pandas as pd data = pd.read_csv('E:/수료증/인프런/밑바닥부터시작하는머신러닝/train.csv') data2 ..
 [통계학] CART 구현을 통한 TITANIC 변수 선택
[통계학] CART 구현을 통한 TITANIC 변수 선택
0. 목표 - CART 알고리즘을 통해 우선적으로 분류되어야 할 변수를 선택 1. 이론 1) Gini Index를 통해 데이터의 대상 속성을 얼마나 잘못 분류할지를 계산 2) 각 속성별(male, female, 1, 2, 3...)로 계산하여 최소값을 계산 2. 데이터셋 준비 1) kaggle 타이타닉 데이터 셋 다운로드(링크에서 titanic 검색) 2) 데이터 전처리 import pandas as pd data = pd.read_csv('E:/수료증/인프런/밑바닥부터시작하는머신러닝/train.csv') data2 = data[['Pclass', 'Sex', 'Survived']] - Pclass : 승선권 클래스(1, 2, 3) - Sex : 성별(male, female) - Survived : 생존..
 [통계학] ID3 구현을 통한 변수 선택
[통계학] ID3 구현을 통한 변수 선택
0. 목표 - 타이타닉 데이터 셋에서 ID3 알고리즘을 통해 우선적으로 분류되어야 할 변수 선택 1. 수식 - Gain(A) = Info(D) - Info A(D) => A의 정보 소득 = 전체 데이터(D)의 정보량 - 속성 A로 분류시 정보량 => 우선적으로 분류되어야 할 변수는 최종 결과값(A의 정보 소득)이 가장 큰 값 2. 준비물 1) kaggle 타이타닉 데이터 셋 다운로드(링크에서 titanic 검색) 2) 데이터 전처리 import pandas as pd data = pd.read_csv('E:/수료증/인프런/밑바닥부터시작하는머신러닝/train.csv') data2 = data[['Pclass', 'Sex', 'Survived']] - Pclass : 승선권 클래스(1, 2, 3) - Sex..
 [통계학] 엔트로피(Entropy)
[통계학] 엔트로피(Entropy)
0. 엔트로피 1) 목적 달성을 위한 경우의 수를 정량적으로 표현한 수치 ex) - 엔트로피가 커짐 -> 불확실성이 커짐 -> 얻을 수 있는 정보가 불명확해짐 - 엔트로피가 작아짐 -> 불확실성이 작아짐 -> 얻을 수 있는 정보가 명확해짐 2) 수식 - Pi가 커지면(1에 수렴하면) -log2(Pi) 는 작아지기에(0에 수렴) 둘을 곱하면 0이 됨 import matplotlib.pyplot as plt a = 0 pi_list = [] log2pi_list = [] for i in range(20): a += 0.05 pi_list.append(a) log2pi_list.append(-log2(a)) plt.plot(pi_list, log2pi_list) plt.xlabel("pi") plt.ylabe..
 [강의수강후기] 한 눈에 끝내는 자바 기초(goorm edu)
[강의수강후기] 한 눈에 끝내는 자바 기초(goorm edu)
0. 강의명 - 한 눈에 끝내는 자바 기초(링크) 1. 내용 - 자바(JAVA) 기초 문법을 실습을 통해 진행 가능 - goorm이 자체적인 ide를 보유하고 있기에(goorm ide) 실습시 효과적
 [강의수강후기] 프로세스 마이닝
[강의수강후기] 프로세스 마이닝
0. 강의명 - 모두를 위한 프로세스 마이닝(링크) - 프로세스 마이닝을 활용한 고객여정분석(링크) - 무료! 1. 프로세스 마이닝 1) 가치 2) 장점 - GA(Google Analytics)는 페이지 방문 빈도, 페이지의 흐름등을 파악하는데 중점을 두는데 반해 프로세스 마이닝은 로그 데이터 기반의 고객여정을 통해 고객 행동을 설명하는 프로세스 모델 발견 가능. - 자동화된 분석 기반을 통해 반복 수행 가능 - 고객의 다양한 행동패턴들을 발견 및 비교 가능 2. 실습 내용 - DISCO 소프트웨어(데모)를 통한 실습 - DISCO 다운로드(링크) 3. 후기 - 기존의 GA는 페이지 뷰 등이 중심이라 회사 내부의 DB와는 동떨어진 느낌이 있었다. DISCO 같은 사용하지 않더라도 위와 같은 분석을 이용하..
 [PYTHON] PyQt5 + pyinstaller를 사용한 twitter 크롤링 프로그램 제작
[PYTHON] PyQt5 + pyinstaller를 사용한 twitter 크롤링 프로그램 제작
0. Flow Chart 1) 사용자가 원하는 키워드를 입력하고 검색 버튼 클릭 2) python을 사용해서 twitter에서 연관 키워드 글 추출 3) pandas를 사용해서 xlsx 형식으로 제공 1. 준비물 1) 트위터 앱 생성(링크) - Create an app을 눌러 생성 - Details 클릭 이후 Keys and tokens의 아래 키들 확인(보관 주의) 2) 필요 라이브러리 설치 pip install PyQt5 pip install pyinstaller pip install tweepy 2. 코드 1) library 호출 import sys from PyQt5.QtWidgets import * import tweepy import pandas as pd from pandas import E..