
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Blog
- 매틀랩
- Linux
- matplotlib
- Ga
- 통계학
- 서평단
- 서평
- 텐서플로
- MATLAB
- 블로그
- SQL
- 월간결산
- 티스토리
- Tistory
- 파이썬
- tensorflow
- 시각화
- MySQL
- Google Analytics
- Python
- Pandas
- 딥러닝
- 리눅스
- python visualization
- 한빛미디어
- 독후감
- 한빛미디어서평단
- Visualization
- 파이썬 시각화
Archives
- Today
- Total
pbj0812의 코딩 일기
[통계학] 엔트로피(Entropy) 본문
0. 엔트로피
1) 목적 달성을 위한 경우의 수를 정량적으로 표현한 수치
ex)
- 엔트로피가 커짐 -> 불확실성이 커짐 -> 얻을 수 있는 정보가 불명확해짐
- 엔트로피가 작아짐 -> 불확실성이 작아짐 -> 얻을 수 있는 정보가 명확해짐
2) 수식
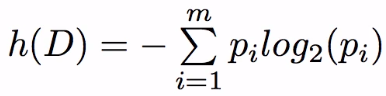
- Pi가 커지면(1에 수렴하면) -log2(Pi) 는 작아지기에(0에 수렴) 둘을 곱하면 0이 됨
import matplotlib.pyplot as plt
a = 0
pi_list = []
log2pi_list = []
for i in range(20):
a += 0.05
pi_list.append(a)
log2pi_list.append(-log2(a))
plt.plot(pi_list, log2pi_list)
plt.xlabel("pi")
plt.ylabel("log2pi")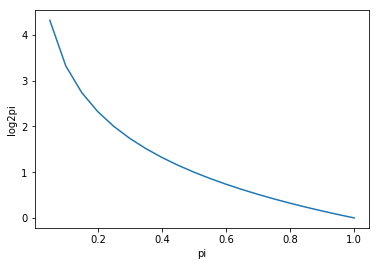
1. 활용
1) 준비물
- 캐글(링크)에서 titanic dataset(train.csv) 다운로드

2) 코드 작성
(1) 라이브러리 호출
import pandas as pd
import matplotlib.pyplot as plt(2) 데이터 호출
data = pd.read_csv('E:/수료증/인프런/밑바닥부터시작하는머신러닝/train.csv')
data.head()
(3) 데이터 길이 확인
data_length = len(data)
print(data_length)(4) 생존자 상태 확인
- Survived column 이용
- 0과 1밖에 없지만 자동화를 이용하기 위해 set으로 받아서 중복을 제거한 뒤 list로 변환
- 결과 : [0, 1]
selection = list(set(data['Survived']))
print(selection)(5) 상태 별 엔트로피 계산
- 결과 : [0.43046238619717303, 0.5302455156784739]
result = []
for i in selection:
survive_i = len(data[data['Survived']==i])/data_length
result.append(-survive_i * log2(survive_i))(6) 합산
- 결과 : 0.9607079018756469
sum(result)2. 참고
1) 밑바닥 부터 시작하는 머신러닝 입문(최성철 교수님)
2) 위키피디아
'Science > 통계학' 카테고리의 다른 글
| [통계학] Python으로 피어슨의 상관계수 구현하기 (0) | 2020.08.14 |
|---|---|
| [통계학] 변동계수(CV) 구현하기 (0) | 2020.08.13 |
| [통계학] CART 구현을 통한 TITANIC 변수 선택 (0) | 2020.03.10 |
| [통계학] ID3 구현을 통한 변수 선택 (0) | 2020.03.09 |
| [통계학] 평균의 종류 (0) | 2019.07.24 |
'Science/통계학' Related Articles
more




Comments