
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Visualization
- 블로그
- Pandas
- MATLAB
- 통계학
- 파이썬 시각화
- MySQL
- 텐서플로
- 한빛미디어
- Tistory
- tensorflow
- 서평단
- Python
- Blog
- Linux
- 매틀랩
- 월간결산
- 독후감
- matplotlib
- 한빛미디어서평단
- SQL
- 시각화
- 파이썬
- 티스토리
- Google Analytics
- 서평
- Ga
- 리눅스
- 딥러닝
- python visualization
Archives
- Today
- Total
pbj0812의 코딩 일기
[자동화] BeautifulSoup을 사용한 유투브 동영상 URL 추출 본문
0. 목표
- 유투브 동영상 URL 추출
- selenium은 너무 느림
1. 실습
1) library 호출
import requests
import pandas as pd
from bs4 import BeautifulSoup2) URL 추출
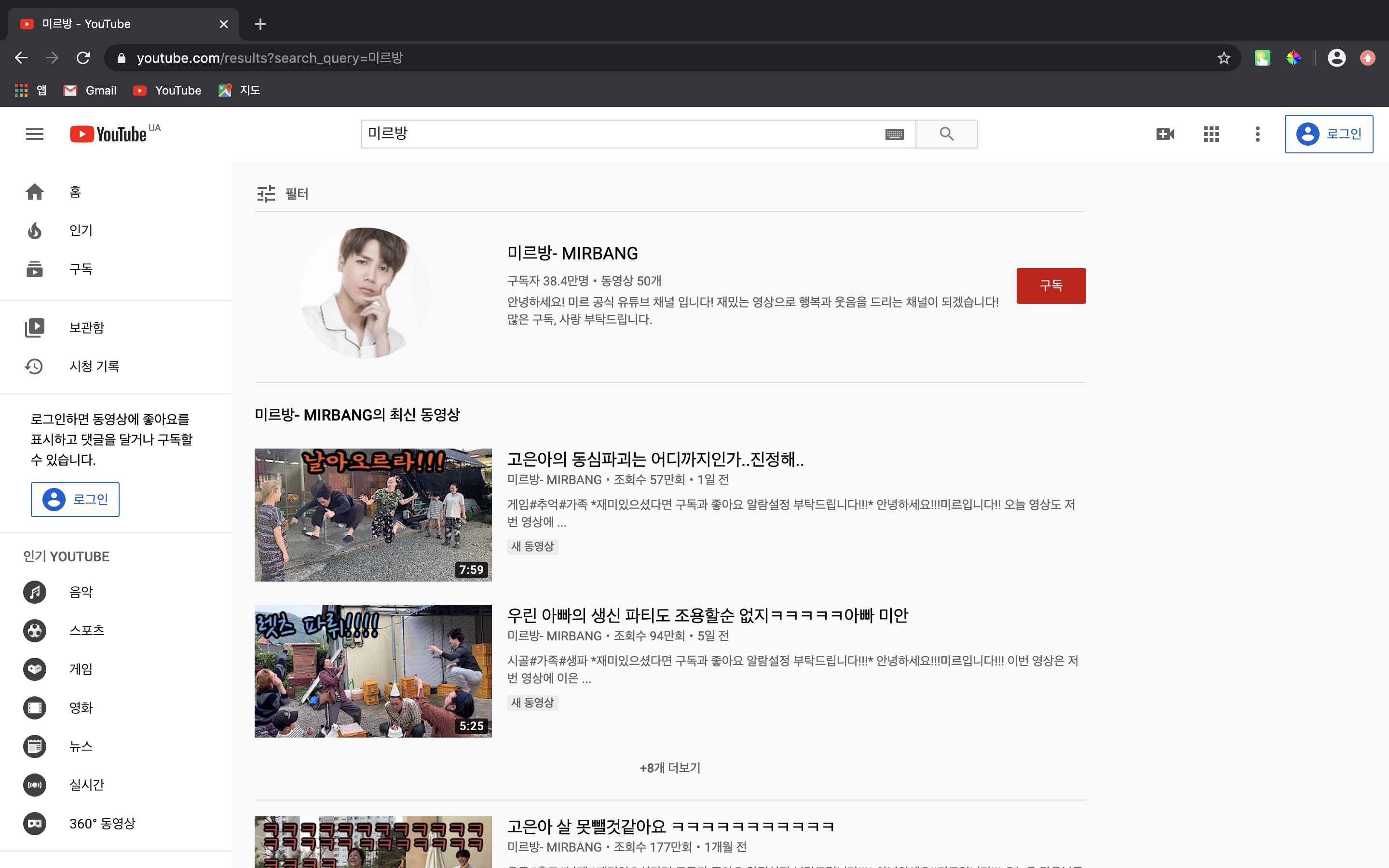
keyword = '미르방'
req = requests.get('https://www.youtube.com/results?search_query=' + keyword)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
my_titles = soup.select(
'h3 > a'
)
title = []
url = []
for idx in my_titles:
title.append(idx.text)
url.append(idx.get('href'))3) 데이터 프레임화
title_list = pd.DataFrame(url, columns = ['url'])
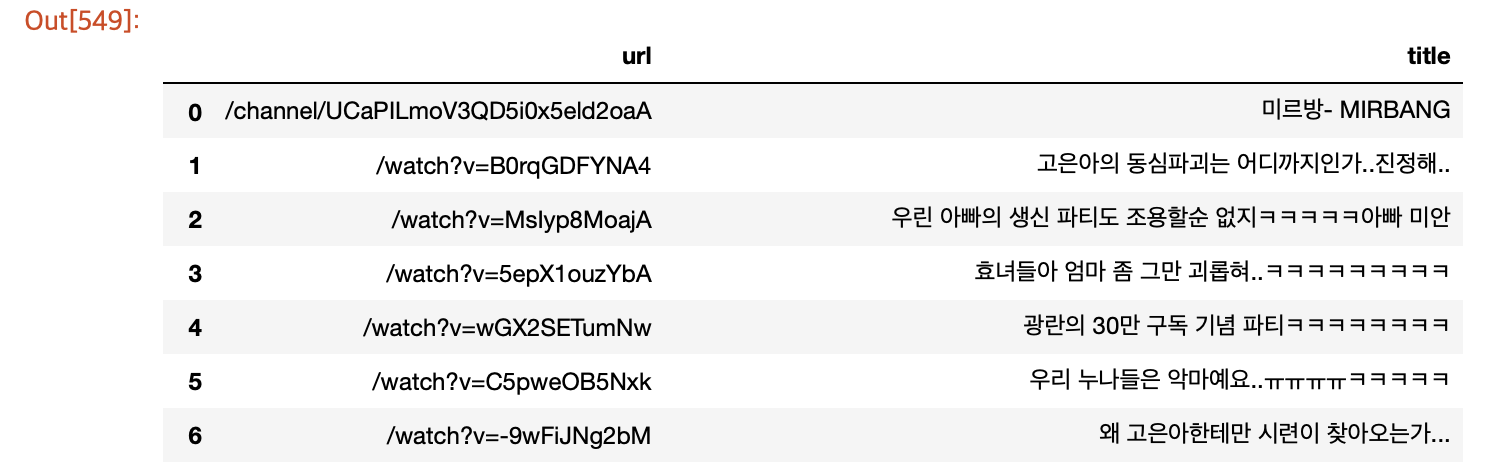
title_list['title'] = title4) 확인
title_list- 채널의 URL도 같이 딸려온 것을 알 수 있음
5) 코드 개선
import requests
import pandas as pd
from bs4 import BeautifulSoup
keyword = '미르방'
req = requests.get('https://www.youtube.com/results?search_query=' + keyword)
html = req.text
soup = BeautifulSoup(html, 'html.parser')
my_titles = soup.select(
'h3 > a'
)
title = []
url = []
for idx in my_titles:
if idx.get('href')[:7] != '/watch?':
pass
else:
title.append(idx.text)
url.append(idx.get('href'))
title_list = pd.DataFrame(url, columns = ['url'])
title_list['title'] = title6) 확인
title_list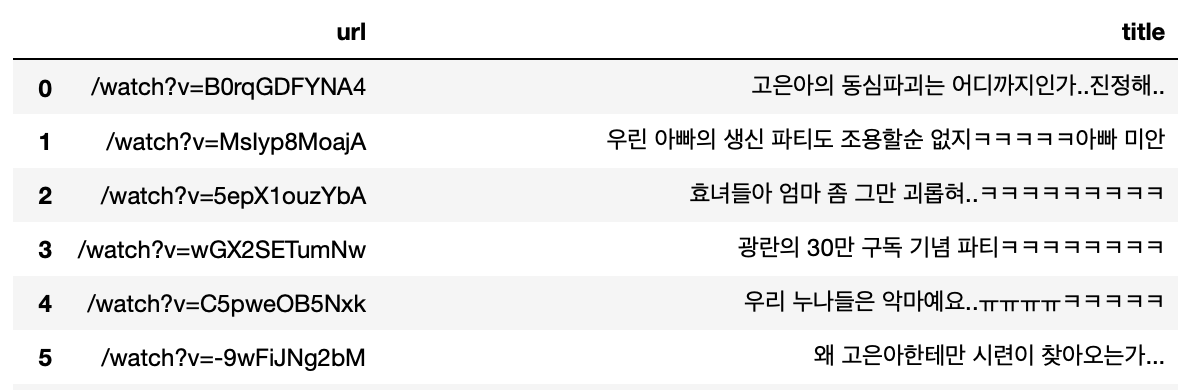
2. 참고
'빅데이터 > 자동화' 카테고리의 다른 글
| [자동화] Python을 이용하여 유투브 댓글 크롤링(남의 소스 사용) (0) | 2020.06.02 |
|---|---|
| [자동화] python을 이용한 유투브 라이브 채널의 정보 및 댓글 크롤링 (22) | 2020.05.31 |
| [자동화] Google Data Studio 대쉬보드 만들기 (0) | 2020.04.16 |
| [자동화] Airflow 예제 (0) | 2020.04.08 |
| [Web] Firebase를 이용한 웹 사이트 만들기 (0) | 2020.02.17 |
'빅데이터/자동화' Related Articles
more




Comments