
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 서평
- python visualization
- Linux
- 티스토리
- 매틀랩
- 독후감
- 통계학
- 텐서플로
- Pandas
- matplotlib
- Google Analytics
- 월간결산
- 딥러닝
- 시각화
- 파이썬
- 파이썬 시각화
- Ga
- 한빛미디어
- MySQL
- Visualization
- Python
- Blog
- 한빛미디어서평단
- MATLAB
- SQL
- 리눅스
- 블로그
- tensorflow
- Tistory
- 서평단
- Today
- Total
pbj0812의 코딩 일기
[자동화] python을 이용한 유투브 라이브 채널의 정보 및 댓글 크롤링 본문
pytchat 이 업그레이드 됨에 따라 문서를 따라하여 만들었으니 혹시 라이브 크롤링이 안되시는 분은 링크 참고 부탁드리겠습니다.
0. 목표
- python을 이용하여 아래 라이브 채널의 댓글 및 채널의 정보 획득

1. flow chart
- 유투브 라이브 채널을 파이썬을 이용하여 정보 및 실시간 댓글을 모으고 실시간으로 csv 파일로 저장하는 형태

2. 문제
- 원하는 정보(실시간 시작일, 채널 명)가 태그 사이가 아닌 스크립트 안에 끼어져 있는 형태

3. 준비
1) library 설치
- pytchat : 실시간 댓글 크롤링 라이브러리
- youtube-dl : pafy 실행을 위해 필요
- pafy : 유투브 정보 긁어 오기
- pafy의 경우 특정 정보(스트리밍 시작일 등)를 얻기 위해서는 youtube api가 필요
pip install youtube-dl
pip install pafy
pip install pytchat2) youtue api 설정
(1) console.developers.google.com/apis/ 접속
- 새 프로젝트 생성
- 라이브러리 클릭
(2) youtube 검색
- YouTube Data API v3 클릭
- 사용설정 클릭

(3) 사용자 인증 정보 클릭
- 사용자 인증 정보 만들기 클릭
- API 키 클릭
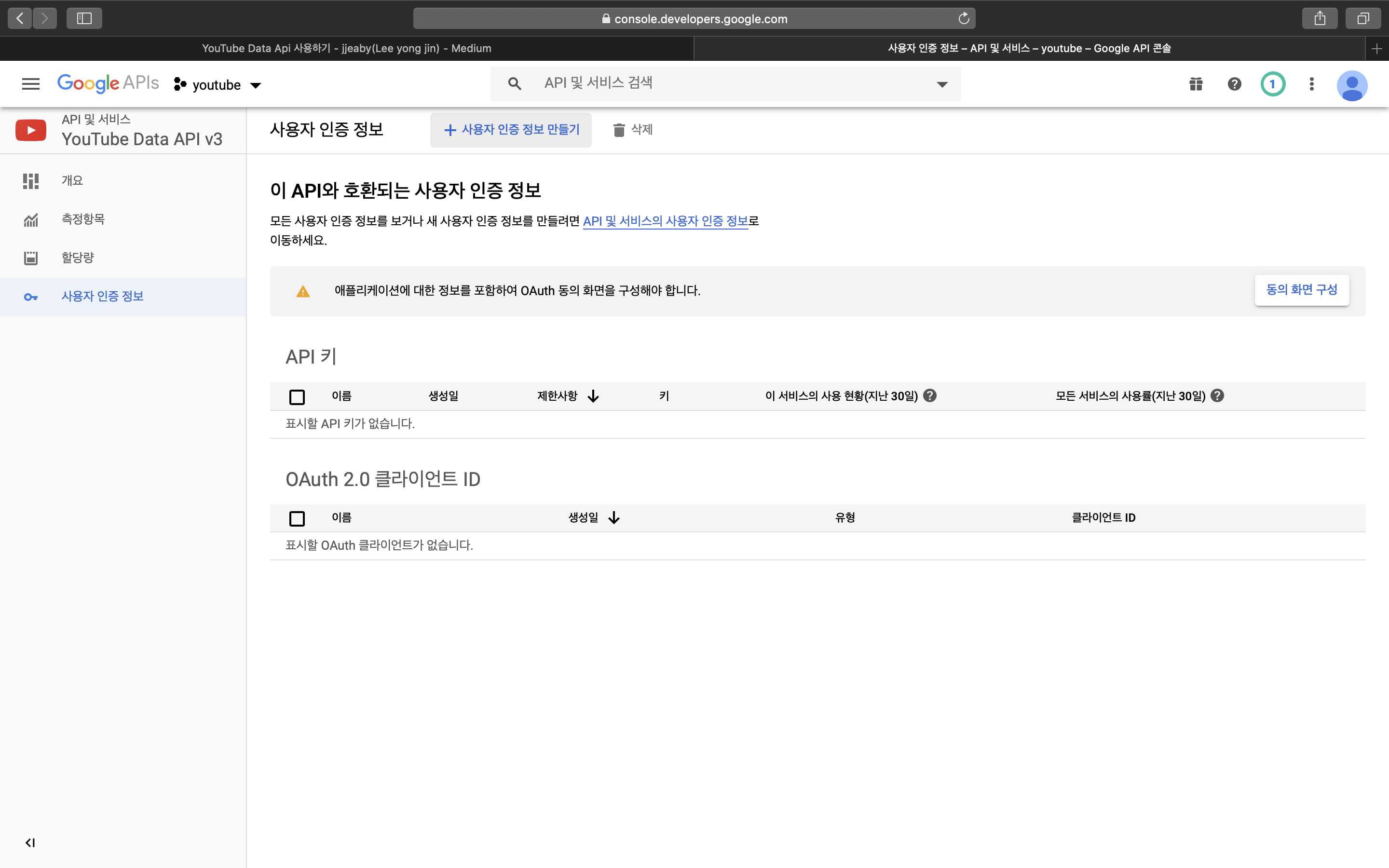
4. 코드 작성
1) library 호출
from pytchat import LiveChat
import pafy
import pandas as pd2) api 설정
- 위 준비 단계에서 얻은 api-key 입력
pafy.set_api_key('api-key 입력')3) 대상 유투브 라이브 방송의 video_id 지정
ex) www.youtube.com/watch?v=VykycecFVoc 라면 VykycecFVoc가 video_id
video_id = '비디오 아이디'4) 라이브 방송 정보 획득
v = pafy.new(video_id)
title = v.title
author = v.author
published = v.published
print(title)
print(author)
print(published)- 결과
[1회부터 120회까지 사골 스트리밍] 2020에도 맛있는 녀석들 [맛있는 녀석들_Tasty Guys]
맛있는 녀석들 (Tasty Guys)
2020-05-29 13:27:59Z5) 빈 csv 생성
empty_frame = pd.DataFrame(columns=['제목', '채널 명', '스트리밍 시작 시간', '댓글 작성자', '댓글 내용', '댓글 작성 시간'])
empty_frame.to_csv('./youtube.csv')- 결과

6) 크롤링 및 결과 csv 추가
- 위에서 빈 프레임으로 제목을 미리 저장했으므로, 실시간으로 정보를 얻은 뒤 헤더를 제외하고 어펜드 하는 형식
chat = LiveChat(video_id = video_id, topchat_only = 'FALSE')
while chat.is_alive():
try:
data = chat.get()
items = data.items
for c in items:
print(f"{c.datetime} [{c.author.name}]- {c.message}")
data.tick()
data2 = {'제목' : [title], '채널 명' : [author], '스트리밍 시작 시간' : [published], '댓글 작성자' : [c.author.name], '댓글 내용' : [c.datetime], '댓글 작성 시간' : [c.message]}
result = pd.DataFrame(data2)
result.to_csv('youtube.csv', mode='a', header=False)
except KeyboardInterrupt:
chat.terminate()
break5. 결과

6. 참고
- pytchat
- pafy
'빅데이터 > 자동화' 카테고리의 다른 글
| [자동화] papermil을 통한 jupyter notebook 실행 (0) | 2020.06.04 |
|---|---|
| [자동화] Python을 이용하여 유투브 댓글 크롤링(남의 소스 사용) (0) | 2020.06.02 |
| [자동화] BeautifulSoup을 사용한 유투브 동영상 URL 추출 (2) | 2020.05.24 |
| [자동화] Google Data Studio 대쉬보드 만들기 (0) | 2020.04.16 |
| [자동화] Airflow 예제 (0) | 2020.04.08 |



