
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- python visualization
- Ga
- Visualization
- 독후감
- matplotlib
- 매틀랩
- 텐서플로
- SQL
- 딥러닝
- Linux
- Tistory
- 티스토리
- tensorflow
- 서평단
- 시각화
- 한빛미디어서평단
- Pandas
- Python
- 리눅스
- 파이썬 시각화
- 한빛미디어
- 서평
- MySQL
- 파이썬
- Google Analytics
- MATLAB
- Blog
- 블로그
- 월간결산
- 통계학
- Today
- Total
목록판다스 (9)
pbj0812의 코딩 일기
 [PYTHON] add_patch 를 이용한 violinplot 구현하기
[PYTHON] add_patch 를 이용한 violinplot 구현하기
0. 목표 - add_patch 를 이용한 violinplot 구현하기 1. seaborn 의 violinplot import seaborn as sns tips = sns.load_dataset("tips") sns.violinplot(y="total_bill", data=tips) 2. 구현하기 1) library 호출 import matplotlib.pyplot as plt import pandas as pd import matplotlib.patches as patches 2) 구간 확보 - [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55] bins = list(range(0, 60, 5)) 3) 구간 적용 tips['level'] = pd.cut(tips['to..
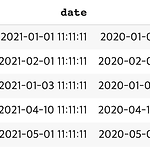 [PYTHON] relativedelta 를 활용한 date_add 구현
[PYTHON] relativedelta 를 활용한 date_add 구현
0. 목표 - relativedelta 를 활용한 date_add 구현 1. 실습하기 1) library 호출 import pandas as pd from dateutil.relativedelta import relativedelta 2) 데이터 프레임 생성 df = pd.DataFrame({'id' : [1, 2, 3, 4, 5], 'date' : ['2021-01-01 11:11:11', '2021-02-01 11:11:11', '2021-01-03 11:11:11', '2021-04-10 11:11:11', '2021-05-01 11:11:11']}) 3) 데이터 형식 변경 df['date'] = pd.to_datetime(df['date'], format="%Y-%m-%d %H:%M:%S") 4)..
 [PYTHON] pandas query 함수 사용하기
[PYTHON] pandas query 함수 사용하기
0. 목표 - query 함수 사용하기 1. 실습하기 1) library 호출 import pandas as pd 2) dataframe 생성 df = pd.DataFrame({'A' : [1, 2, 3, 4, 5], 'B' : ['apple', 'banana', 'apple', 'berry', 'watermelon']}) 3) query 사용하기 (1) where A > 3 df.query('A > 3') (2) where A > 3 and A 3 and A < 5') (3) where A = 1 or A = 4 df.query('A == 1 or A == 4') (4) where A in (1, 3, 5) df.query("A in (1, 3, 5)") (5) wher..
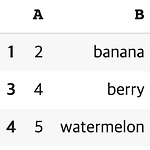 [PYTHON] isin 으로 SQL in, not in 구현
[PYTHON] isin 으로 SQL in, not in 구현
0. 목표 - isin 으로 SQL in 구현 1. 실습하기 1) library 호출 import pandas as pd 2) 테이블 생성 df = pd.DataFrame({'A' : [1, 2, 3, 4, 5], 'B' : ['apple', 'banana', 'apple', 'berry', 'watermelon']}) 3) isin 으로 in 구현 df[df.B.isin([1, 'apple'])] 4) isin 으로 not in 구현 df[~df.B.isin([1, 'apple'])] 2. 참고 - How to filter Pandas dataframe using 'in' and 'not in' like in SQL
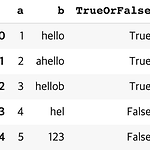 [PYTHON] lambda 와 정규표현식을 이용한 SQL like 구현
[PYTHON] lambda 와 정규표현식을 이용한 SQL like 구현
0. 목표 - lambda 와 정규표현식을 이용한 SQL like 구현 1. 실습 1) library 호출 import pandas as pd import re 2) 데이터 프레임 생성 df = pd.DataFrame({'a' : [1, 2, 3, 4, 5], 'b' : ['hello', 'ahello', 'hellob', 'hel', '123']}) 3) 함수 생성 - 정규식을 이용하여 결과가 re.Match 이면 True 반환 아니면 False 반환 def function(x, inp): p = re.compile(inp) m = p.search(x) return type(m) == re.Match 4) %hello% df['TrueOrFalse'] = df.apply(lambda x : functi..
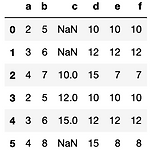 [PYTHON] transform 을 사용한 데이터 변환
[PYTHON] transform 을 사용한 데이터 변환
0. 목표 - transform 을 사용한 데이터 변환 1. 실습 1) library 호출 import pandas as pd 2) 데이터 프레임 생성 df = pd.DataFrame({'a' : [1, 2, 3, 1, 2, 3], 'b' : [4, 5, 6, 4, 5, 7]}) 3) 모든 데이터에 1 씩 더하기 df2 = df.transform(lambda x : x + 1) 4) 데이터 프레임 옆에 groupby 결과를 넣고 싶을 때 (1) groupby 만 사용해보기 - groupby 결과가 index 별 숫자이기에 딸려 들어간 형태 - a 로 그룹화할 때 b의 합은 2 : 10, 3 : 12, 4 : 15 이기에 인덱스 찾아감 df2['c'] = df2.groupby(by = ['a'])['b']..
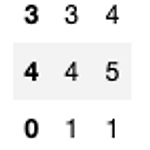 [PYTHON] pandas 로 UNION 구현하기
[PYTHON] pandas 로 UNION 구현하기
0. 목표 - pandas 로 UNION 구현하기 1. 실습 1) library 호출 import pandas as pd 2) 데이터 프레임 생성 a = pd.DataFrame({'a' : [1, 1, 2, 3, 4], 'b' : [1, 2, 3, 4, 5]}) b = pd.DataFrame({'a' : [1, 2, 3, 4, 5], 'b' : [1, 3, 5, 5, 9]}) 3) 데이터 프레임 결합 c = pd.concat([a, b]) 4) 중복 제거 - inplace 옵션을 통한 변수에 바로 저장 c.drop_duplicates(inplace = True) 5) index 초기화 - inplace 옵션을 통한 변수에 바로 저장 c.reset_index(drop = True, inplace = Tru..
 [kaggle] pandas 수료과정
[kaggle] pandas 수료과정
0. 목차 및 내용 1) Creating, Reading and Writing - DataFrame 제작 방법(개인적으로는 dict 형태로만 썼었는데, 아래와 같이 쓸 수도 있음) fruit_sales = pd.DataFrame([[35, 21], [41, 34]], columns=['Apples', 'Bananas'], index=['2017 Sales', '2018 Sales']) - Series 에 관한 설명 - read_csv 를 통한 csv 파일 읽기 2) Indexing, Selecting & Assigning - iloc과 loc의 차이(iloc 은 stdlib indexing 기반 이기에 0:10 의 결과가 10개 나오지만 loc 은 11개가 나옴) - 해당 조건에 맞는 결과 추출 - 열 ..
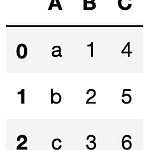 [Python] pandas melt 도큐먼트 따라하기
[Python] pandas melt 도큐먼트 따라하기
0. 묵표 - pandas melt 도큐먼트 따라하기 1. 실습 1) library 호출 import pandas as pd 2) 데이터 생성 df = pd.DataFrame({'A' : ['a', 'b', 'c'], 'B' : [1, 2, 3], 'C' : [4, 5, 6]}) 3) melt 예제 따라하기 (1) pd.melt(df, id_vars=['A'], value_vars=['B']) (2) pd.melt(df, id_vars=['A'], value_vars=['C']) (3) pd.melt(df, id_vars=['A'], value_vars=['B', 'C']) (4) 필드명 변경 pd.melt(df, id_vars = ['A'], value_vars = ['B'], var_name = 'v..