
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Blog
- 파이썬
- Pandas
- 리눅스
- MySQL
- 통계학
- 독후감
- Python
- Google Analytics
- 시각화
- 파이썬 시각화
- 서평
- 블로그
- Linux
- MATLAB
- 티스토리
- matplotlib
- 월간결산
- 서평단
- 매틀랩
- Visualization
- SQL
- 텐서플로
- 한빛미디어
- 딥러닝
- python visualization
- 한빛미디어서평단
- Ga
- Tistory
- tensorflow
- Today
- Total
목록데이터 전처리 (7)
pbj0812의 코딩 일기
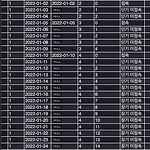 [SQL] 이탈 회원 확인
[SQL] 이탈 회원 확인
0. 목표 - 이탈 회원 확인 1. 실습 1) 테이블 생성 CREATE TABLE sql_test.login_table ( id int, when_login datetime ); 2) 데이터 삽입 INSERT INTO sql_test.login_table(id, when_login) VALUES(1, '2022-01-01 00:00:00'); INSERT INTO sql_test.login_table(id, when_login) VALUES(1, '2022-01-02 00:00:00'); INSERT INTO sql_test.login_table(id, when_login) VALUES(2, '2022-01-03 00:00:00'); INSERT INTO sql_test.login_table(id, wh..
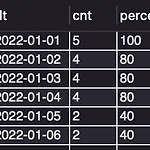 [SQL] rolling retention 계산
[SQL] rolling retention 계산
0. 목표 - rolling retention 계산 1. 실습 1) 데이터 만들기 - 링크 2) 쿼리 작성 (1) 각 id 별 첫 번째 접속일과 마지막 접속일 연산 WITH summary AS ( SELECT id, MIN(dated) AS first_login, MAX(dated) AS last_login FROM sql_test.classic_retention GROUP BY 1 ORDER BY 1 ), (2) 달력 생성 Calendar AS ( SELECT CONCAT(y, '0101') + INTERVAL tt*1000 + a*100 + b*10 + c DAY AS dt FROM (SELECT 0 AS tt UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SE..
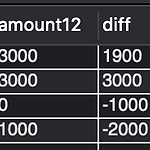 [SQL] 전월 대비 실적 파악하기
[SQL] 전월 대비 실적 파악하기
0. 목표 - 전월 대비 실적 파악하기 1. 실습 1) 테이블 생성 CREATE TABLE sql_test.full_test ( id int, amount int, dated datetime ); 2) 데이터 삽입 INSERT INTO sql_test.full_test(id, amount, dated) VALUES(1, 100, '2021-11-12 12:12:12'); INSERT INTO sql_test.full_test(id, amount, dated) VALUES(1, 1000, '2021-11-12 12:12:12'); INSERT INTO sql_test.full_test(id, amount, dated) VALUES(3, 1000, '2021-11-12 12:12:12'); INSERT IN..
 [독후감] Python과 SQL을 활용한 실전 데이터 전처리
[독후감] Python과 SQL을 활용한 실전 데이터 전처리
0. 도서 정보 - 도서명 : Python과 SQL을 활용한 실전 데이터 전처리 - 저자 : 이현호 - 링크 1. 후기 - 디자인 : 작고 길쭉한 형태(포켓북의 느낌...), 그래서 들고 다니기에는 편하지만 길쭉한 나머지 글(코드)을 읽기가 힘들다. 이 부분에선 좀 아쉽다고 볼 수 있다. 글이 눈에 안들어오는 느낌... - 책의 구성 : 데이터 전처리에 대한 기본적인 이론 설명을 나열한 뒤, 실제 파일로(공공 데이터) 해당 전처리를 하는 방식이다. 해당 처리에 대하여 SQL 에서는 이렇게 하고, Python 에서는 이렇게 한다의 방식이 아닌 SQL 코드를 Python 이 감싸는 형태로 진행한다. 예를 들면, SQL 에서는 이정도까지만 데이터를 뽑고, Python 에서는 나머지 통계처리를 한다던지 하는....
 [kaggle] Data Cleaning 수료과정
[kaggle] Data Cleaning 수료과정
0. 목차 및 내용 1) Handling Missing Values - NULL 이 포함된 데이터에 대한 처리 - dropna() 를 통한 행 제외 - dropna(axis=1) 를 통한 열 제외 - fillna(0) 를 통한 처리 - fillna(method='bfill', axis=0).fillna(0) 를 통한 대체 2) Scaling and Normalization - Scaling 과 Normalization 의 차이(Scaling 은 값의 범위를 바꾸는 것?, 1달러와 1엔의 예를 들었을 때 1달러는 100엔의 가치가 있음. 이때, Scaling 을 하지 않으면 1엔의 차이와 1달러의 차이는 비슷해짐. Normalization 은 데이터 분포의 형태를 바꾸는 것?) - mlxtend.prepr..
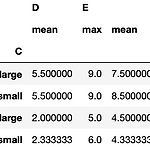 [Python] Pandas pivot, pivot_table 문서 따라하기
[Python] Pandas pivot, pivot_table 문서 따라하기
0. 목표 - pivot, pivot_table 문서 따라하기 1. pivot 1) library 호출 import pandas as pd 2) 데이터 생성 df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two', 'two'], 'bar': ['A', 'B', 'C', 'A', 'B', 'C'], 'baz': [1, 2, 3, 4, 5, 6], 'zoo': ['x', 'y', 'z', 'q', 'w', 't']}) 3) - foo 를 행기준으로 bar 를 열 기준으로 baz 를 채워넣기 df.pivot(index='foo', columns='bar', values='baz') 4) - 3) 과 동일한 결과 df.pivot(index='foo', col..
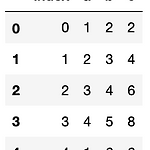 [Python] Pandas 를 이용한 SQL 스러운 데이터 전처리
[Python] Pandas 를 이용한 SQL 스러운 데이터 전처리
0. 목표 - Python 의 Pandas 를 이용하여 SQL 스럽게 데이터 전처리 하기 1. 실습 1) SELECT (1) 필드 하나 df = pd.DataFrame({'a' : [1, 2, 3, 4, 1], 'b' : [2, 3, 4, 5, 6], 'c' : [2, 4, 6, 8, 6]}) df['a'] (2) 필드 여러개 df[['a', 'b']] (3) 행 인덱스로 접근 df.loc[0] 2) WHERE - a 가 3 이상 df[df['a'] >= 3] - a 가 3 이상이고 b 가 5 미만 a = ((df['a'] >= 3) & (df['b'] < 5)) df.loc[a] 3) CASE def case(x): if x < 2: return '2 미만' elif x < 4: return '4 미만..