
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- MATLAB
- MySQL
- python visualization
- SQL
- 서평
- 텐서플로
- matplotlib
- 딥러닝
- Blog
- 한빛미디어
- 블로그
- Tistory
- Ga
- 티스토리
- 월간결산
- 파이썬
- 통계학
- tensorflow
- Python
- 한빛미디어서평단
- 독후감
- Linux
- Pandas
- 서평단
- Visualization
- 리눅스
- 매틀랩
- 파이썬 시각화
- Google Analytics
- 시각화
- Today
- Total
목록전체 글 (596)
pbj0812의 코딩 일기
0. 이론 - 준비한 데이터에서 복원 추출을 반복해 많은 재표본을 생성하고, 그 통계량에서 모수를 추정 1. 실습 1) library 호출 import numpy as np import matplotlib.pyplot as plt import pandas as pd import random import statistics 2) 데이터 생성 - t 분포 를 활용한 신뢰구간 : 1.03 ~ 4.97 x = [1, 2, 3, 4, 5] print('신뢰구간 : ', round(np.mean(x) - 2.78 * 0.71, 2), ' ~ ', round(np.mean(x) + 2.78 * 0.71, 2)) 3) 부트스트랩 - 5개씩 뽑아서(복원추출) 평균을 만들고 해당 데이터들을 통해 신뢰구간 구현 var = ..
 [통계학] 중심극한정리 구현
[통계학] 중심극한정리 구현
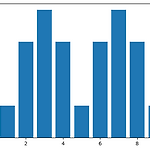
0. 이론 - 개별 데이터의 모집단이 정규분포하지 않아도 거기서 추출한 표본이 충분히 크면 표본평균은 정규분포를 따른다. 1. 실습 1) library 호출 import matplotlib.pyplot as plt import pandas as pd import random 2) 데이터 생성 및 확인 - 봉우리 두 개를 가진 데이터 x = [1] * 25 + [2] * 75 + [3] * 100 + [4] * 75 + [5] * 25 + [6] * 75 + [7] * 100 + [8] * 75 + [9] * 25 df = pd.DataFrame({'x': x}) df2 = df.groupby('x').agg({'x' : 'count'}) plt.bar(df2.index, df2['x']) 3) 한 세트에..

 [독후감] FastAPI를 사용한 파이썬 웹 개발
[독후감] FastAPI를 사용한 파이썬 웹 개발
"한빛미디어 활동을 위해서 책을 제공받아 작성된 서평입니다." 0. 도서정보 - 도서명 : FastAPI를 사용한 파이썬 웹 개발 - 저자 : 압둘라지즈 압둘라지즈 아데시나 - 링크 : https://product.kyobobook.co.kr/detail/S000201188332 1. 서평 - FastAPI 를 들어본 지는 꽤 되었으나 실체를 본 적은 한 번도 없다. 개인적으로 쟝고나 플라스크의 튜토리얼은 해보았으나 FastAPI 는 하지 못하였고, 그것이 이번 서평을 지원하게 된 이유이기도 하다. 기본적으로 파이썬은 알고 있다는 전제하여 진행되며 해당도서를 통하여 git, 파이썬의 가상환경, 도커 등에 대한 간단한 지식도 얻을 수 있다. 이러한 지식은 1장에서 배울 수 있으며, 2장에서는 간단한 프로젝..
