
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Tistory
- Blog
- 한빛미디어서평단
- 리눅스
- 텐서플로
- 파이썬 시각화
- Linux
- 파이썬
- 서평단
- Google Analytics
- 블로그
- Pandas
- 월간결산
- 티스토리
- Ga
- MySQL
- 한빛미디어
- tensorflow
- matplotlib
- Visualization
- 독후감
- Python
- 통계학
- SQL
- 매틀랩
- MATLAB
- 서평
- 시각화
- python visualization
- 딥러닝
- Today
- Total
pbj0812의 코딩 일기
[빅데이터기술] Mac OS에 PySpark 설치 본문
0. 목표
- PySpark 설치
1. 설치
1) java 설치 확인
java -version- 결과
java version "12.0.2" 2019-07-16
Java(TM) SE Runtime Environment (build 12.0.2+10)
Java HotSpot(TM) 64-Bit Server VM (build 12.0.2+10, mixed mode, sharing)* java가 설치되어 있지 않으면 설치 필요 (참고)
2) PySpark 설치
pip install pyspark2. 확인 + 에러잡기
1) cmd 환경
(1) 창에 pyspark 입력
* 아래와 같은 문구가 포함된 에러가 발생하는 경우
Service 'sparkDriver' failed after 16 retries (on a random free port)!
1️⃣ cmd 창에 hostname 입력
- 결과
pbj0812ui-MacBookPro.local2️⃣ /etc/hostname 변경(readonly 파일이므로 sudo로 변경)
- 7 번째 줄처럼 문구를 삽입
1 ##
2 # Host Database
3 #
4 # localhost is used to configure the loopback interface
5 # when the system is booting. Do not change this entry.
6 ##
7 127.0.0.1 pbj0812ui-MacBookPro.local
8 127.0.0.1 localhost
9 255.255.255.255 broadcasthost
10 ::1 localhost
11 # Added by Docker Desktop
12 # To allow the same kube context to work on the host and the container:
13 127.0.0.1 kubernetes.docker.internal
14 # End of section- 다시 pyspark 확인

(2) version 확인
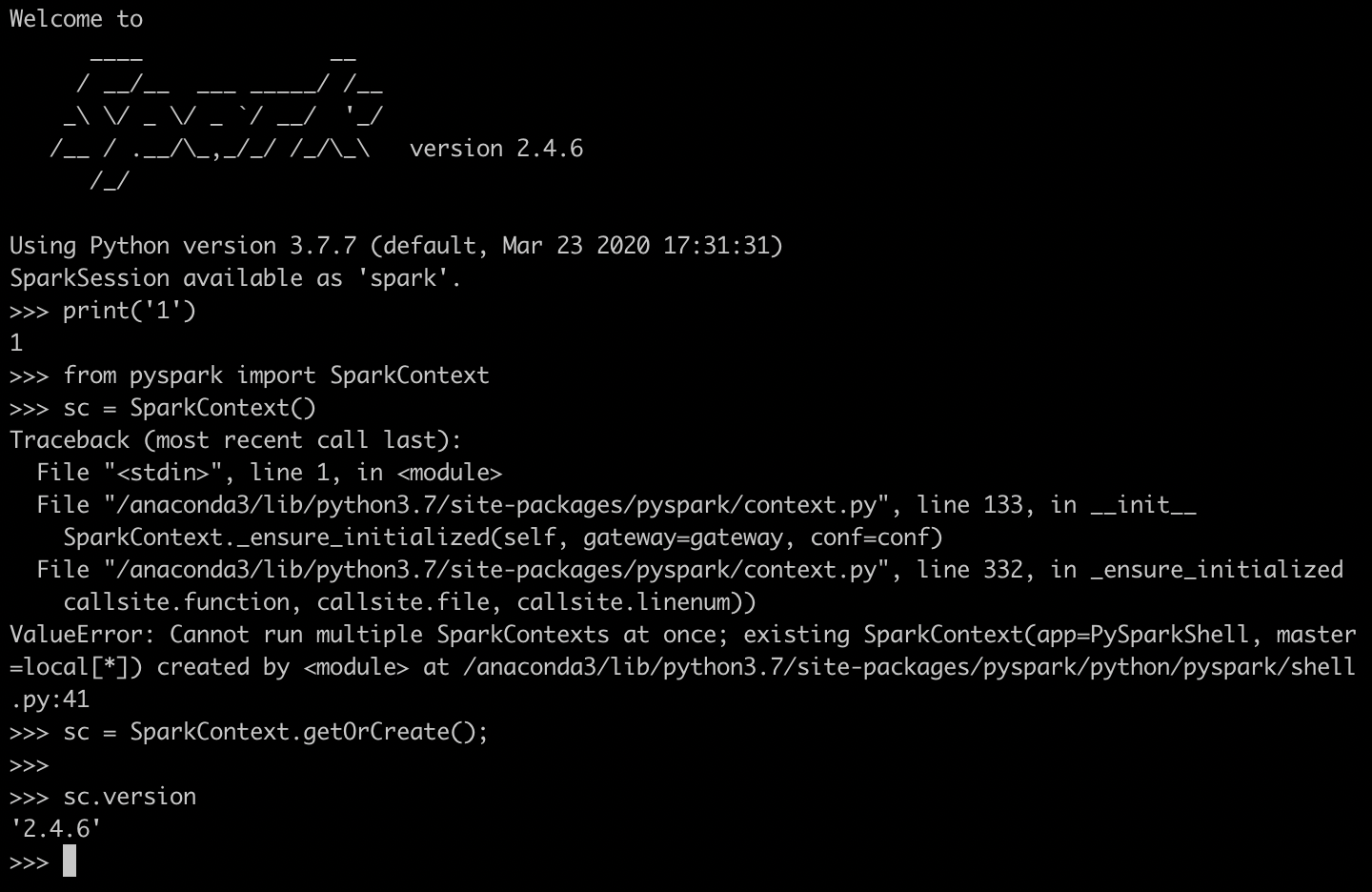
from pyspark import SparkContext
sc = SparkContext()* 아래와 같은 에러가 발생하는 경우
ValueError: Cannot run multiple SparkContexts at once;- 아래와 같이 입력
sc = SparkContext.getOrCreate();- 결과(sc.version)
- 실습
nums = sc.parallelize([1, 2, 3, 4])
nums.map(lambda x : x*x).collect()* 아래와 같은 에러가 발생할 경우
Unsupported class file major version 55- 아래와 같이 입력하고 pyspark 재 실행
export JAVA_HOME=$(/usr/libexec/java_home -v 1.8)- 결과

2) jupyter notebook 환경
from pyspark import SparkContext
sc = SparkContext()
sc.version* 아래와 같은 에러가 발생할 경우
ValueError: Cannot run multiple SparkContexts at once;- 아래와 같이 입력
from pyspark import SparkContext
sc = SparkContext.getOrCreate();
sc.version- 혹은 jupyter notebook 실행시 아래와 같이 입력
jupyter notebook --ip=127.0.0.1- 결과(이때 2번 라인을 한 번 더 실행하게 되면 에러 발생 => 이때는 getOrCreate()로 해결하거나 커널을 리스타트 하면 해결)

- 실습
from pyspark import SparkContext
sc = SparkContext.getOrCreate();
sc.version
nums = sc.parallelize([1, 2, 3, 4])
nums.map(lambda x : x*x).collect()
* 아래와 같은 에러 발생시 (export JAVA_HOME=$(/usr/libexec/java_home -v 1.8)) 이후 jupyter notebook 실행
Unsupported class file major version 56- 결과
[1, 4, 9, 16]3. 참고
- ValueError: Cannot run multiple SparkContexts at once;
- Service 'sparkDriver' failed after 16 retries (on a random free port)!
'빅데이터 > 빅데이터기술' 카테고리의 다른 글
| [빅데이터기술] Docker 이미지 파일 생성 (0) | 2020.12.11 |
|---|---|
| [빅데이터] MacOS 에 hadoop 설치 (0) | 2020.11.18 |
| [빅데이터기술] QWIKLABS를 통한 BigQuery 실습 (0) | 2020.05.14 |
| [빅데이터] elasticsearch + kibana 설치 및 튜토리얼 (windows 환경) (0) | 2020.03.23 |
| [빅데이터] Mac OS에 elasticsearch 설치 (0) | 2019.12.03 |



