
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- MATLAB
- 파이썬
- 독후감
- 텐서플로
- 티스토리
- Ga
- matplotlib
- 딥러닝
- python visualization
- Visualization
- Python
- 한빛미디어서평단
- Blog
- Google Analytics
- SQL
- 리눅스
- 파이썬 시각화
- 서평
- tensorflow
- MySQL
- 서평단
- 매틀랩
- Tistory
- 통계학
- 월간결산
- 블로그
- 한빛미디어
- 시각화
- Pandas
- Linux
Archives
- Today
- Total
pbj0812의 코딩 일기
[자동화] youtube api를 통한 youtube 게시글 댓글 크롤링 본문
0. 목표
- youtube api를 통한 댓글 크롤링
1. 준비물
1) API 키 받기
- 참고 : pbj0812.tistory.com/259
[자동화] python을 이용한 유투브 라이브 채널의 정보 및 댓글 크롤링
0. 목표 - python을 이용하여 아래 라이브 채널의 댓글 및 채널의 정보 획득 1. flow chart - 유투브 라이브 채널을 파이썬을 이용하여 정보 및 실시간 댓글을 모으고 실시간으로 csv 파일로 저장하는
pbj0812.tistory.com
2) OAuth 2.0 클라이언트 ID 받기
(1) + 사용자 인증 정보 만들기 -> OAuth 클라이언트 ID
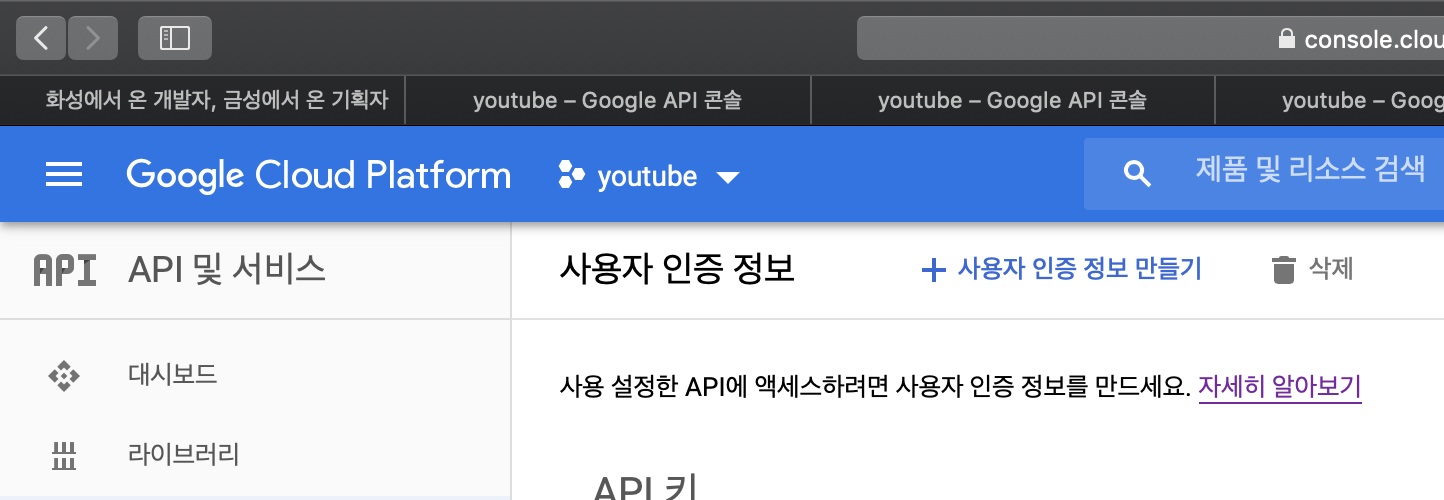
(2) 데스크톱 앱 -> 만들기
(3) 맨 오른쪽의 다운로드 버튼을 눌러 다운로드

3) library 설치
pip install --upgrade google-api-python-client
pip install --upgrade google-auth-oauthlib google-auth-httplib22. 코드 작성
1) library 호출
import pickle
import csv
import os
import google.oauth2.credentials
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request2) paramer 지정
- json 파일은 1 2) (3) 에서 받은 json 파일
CLIENT_SECRETS_FILE = "/Users/pbj0812/Desktop/client_secret.json"
SCOPES = ['https://www.googleapis.com/auth/youtube.force-ssl']
API_SERVICE_NAME = 'youtube'
API_VERSION = 'v3'3) 인증 모듈
def get_authenticated_service():
credentials = None
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
credentials = pickle.load(token)
# Check if the credentials are invalid or do not exist
if not credentials or not credentials.valid:
# Check if the credentials have expired
if credentials and credentials.expired and credentials.refresh_token:
credentials.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(
CLIENT_SECRETS_FILE, SCOPES)
credentials = flow.run_console()
# Save the credentials for the next run
with open('token.pickle', 'wb') as token:
pickle.dump(credentials, token)
return build(API_SERVICE_NAME, API_VERSION, credentials = credentials) 4) 댓글 수집
- 댓글 내용, 작성 시각, 작성자 명 수집
- 얻을 수 있는 내용은 공식 문서 참고
def get_video_comments(service, **kwargs):
comments = []
results = service.commentThreads().list(**kwargs).execute()
while results:
for item in results['items']:
comment = item['snippet']['topLevelComment']['snippet']['textDisplay']
comment2 = item['snippet']['topLevelComment']['snippet']['publishedAt']
comment3 = item['snippet']['topLevelComment']['snippet']['authorDisplayName']
print(comment)
print(comment2)
print(comment3)
print('==============================')
comments.append(comment)
# Check if another page exists
if 'nextPageToken' in results:
kwargs['pageToken'] = results['nextPageToken']
results = service.commentThreads().list(**kwargs).execute()
else:
break
return comments5) 실행 부분
if __name__ == '__main__':
# When running locally, disable OAuthlib's HTTPs verification. When
# running in production *do not* leave this option enabled.
os.environ['OAUTHLIB_INSECURE_TRANSPORT'] = '1'
service = get_authenticated_service()
video_id = input('Enter a video_id: ')
get_video_comments(service, part='snippet', videoId=video_id, textFormat='plainText')3. 실행
1) 첫 실행시 아래와 같은 문구가 뜨면 해당 URL로 들어가 다 승인해주고 마지막에 나오는 code를 입력

2) video_id 입력
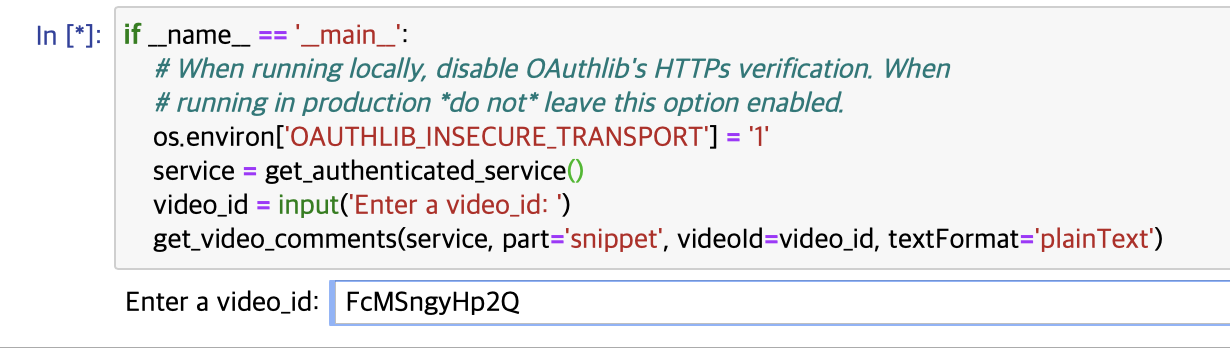
3) 결과

4) 비교
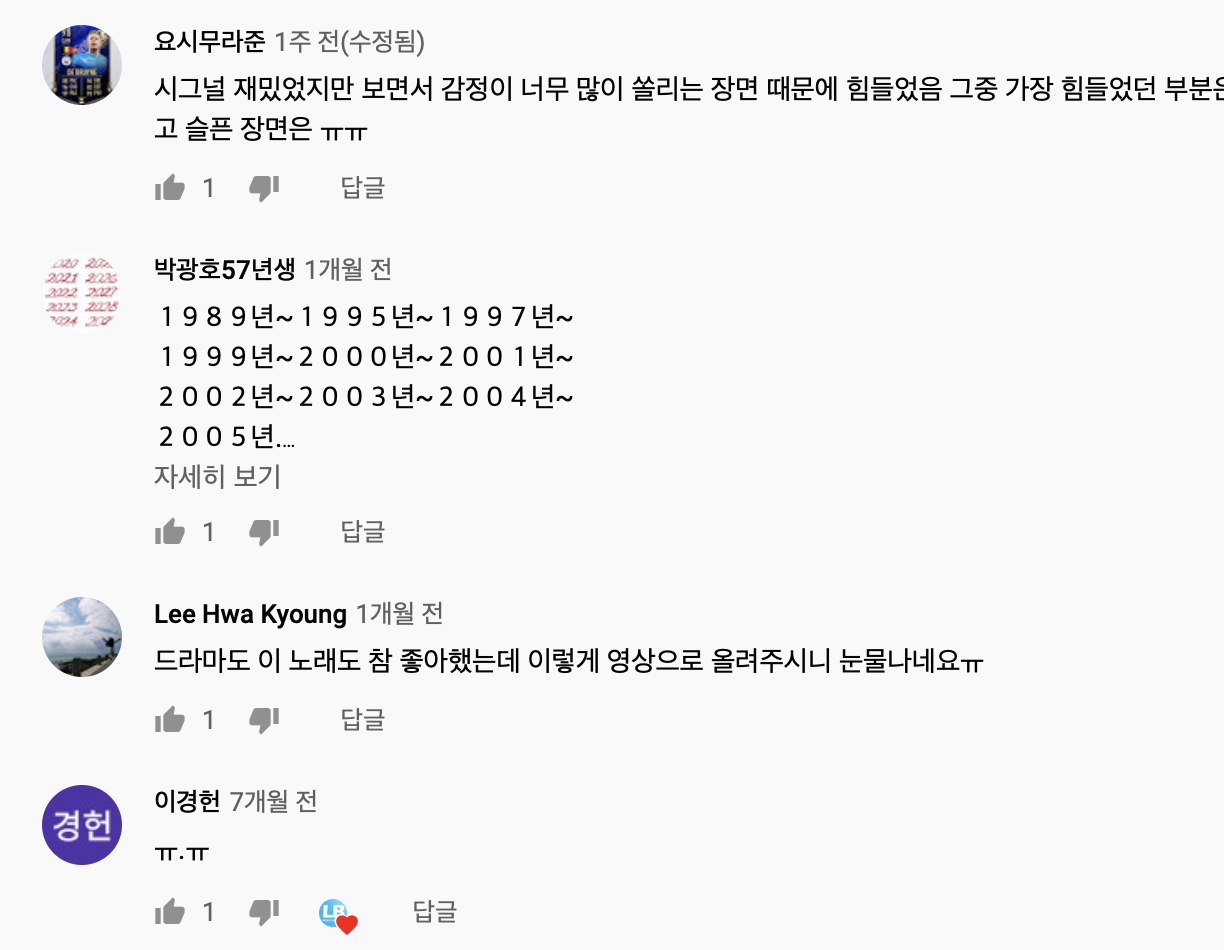
* 요청시마다 코스트가 발생하므로 코스트 가늠 필요 : 코스트 계산기
4. 참고
- 코드 원본
'빅데이터 > 자동화' 카테고리의 다른 글
| [자동화] Grafana + MySQL 연동 (4) | 2020.06.11 |
|---|---|
| [자동화] Mac OS에 Grafana 설치 (1) | 2020.06.10 |
| [자동화] papermil을 통한 jupyter notebook 실행 (0) | 2020.06.04 |
| [자동화] Python을 이용하여 유투브 댓글 크롤링(남의 소스 사용) (0) | 2020.06.02 |
| [자동화] python을 이용한 유투브 라이브 채널의 정보 및 댓글 크롤링 (22) | 2020.05.31 |
'빅데이터/자동화' Related Articles
more




Comments