
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- Python
- 서평단
- python visualization
- 한빛미디어
- Pandas
- 티스토리
- Google Analytics
- Ga
- Visualization
- Linux
- tensorflow
- 블로그
- 파이썬
- 한빛미디어서평단
- 텐서플로
- MySQL
- 시각화
- 딥러닝
- 파이썬 시각화
- 매틀랩
- 월간결산
- Blog
- 독후감
- 서평
- MATLAB
- Tistory
- matplotlib
- SQL
- 통계학
- 리눅스
- Today
- Total
pbj0812의 코딩 일기
[PYTORCH] 03_pytorch with examples (autograd) 본문
Pytorch with examples (autograd) 코드 분석
- 아래 글은 파이토치 튜토리얼 중 autograd 부분을 학습하여 영상으로 만든 것을 재구성한 글입니다.
원본링크 : https://pytorch.org/tutorials/beginner/pytorch_with_examples.html
유투브 영상 : https://youtu.be/U6cOIda_9y0
Autograd 장점
- backward 계산시 수동으로 직접 구현할 필요가 없다.
코드 프리뷰

- 전체적으로 짧아졌다.
기본구조

- 기존과 동일하다.
Device setting
dtype = torch.float
# device = torch.device("cpu")
device = torch.device("cuda:0")
'''지난시간
dtype = torch.float
# device = torch.device("cpu")
device = torch.device("cuda:0")
'''- 지난글과 동일하다
- 첫 번째 줄에서는 tensor를 사용하기 위한 데이터 타입을 지정하였다.
- 아랫줄에서는 CPU를 선택할 지 GPU를 선택할 지 지정하는 구문이다.
- CPU를 사용하고 싶으면 두번째 줄의 주석을 풀고, GPU를 사용하고 싶으면 세번째 줄의 주석을 풀어준다.
Hyper parameter setting
N, D_in, H, D_out = 64, 1000, 100, 10
learning_rate = 1e-6
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True)
''' 지난시간
N, D_in, H, D_out = 64, 1000, 100, 10
learning_rate = 1e-6
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
w1 = torch.randn(D_in, H, device=device, dtype=dtype)
w2 = torch.randn(H, D_out, device=device, dtype=dtype)
'''
- 하이퍼 파라미터 세팅 부분이다.
- requires_grad=True 는 해당 파라미터를 추적하겠다는 의미이다. gradient를 계산하기 위해서 필요하다.
h layer 생성부터 y_pred 생성까지
y_pred = x.mm(w1).clamp(min=0).mm(w2)
'''지난시간
h = x.mm(w1)
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
'''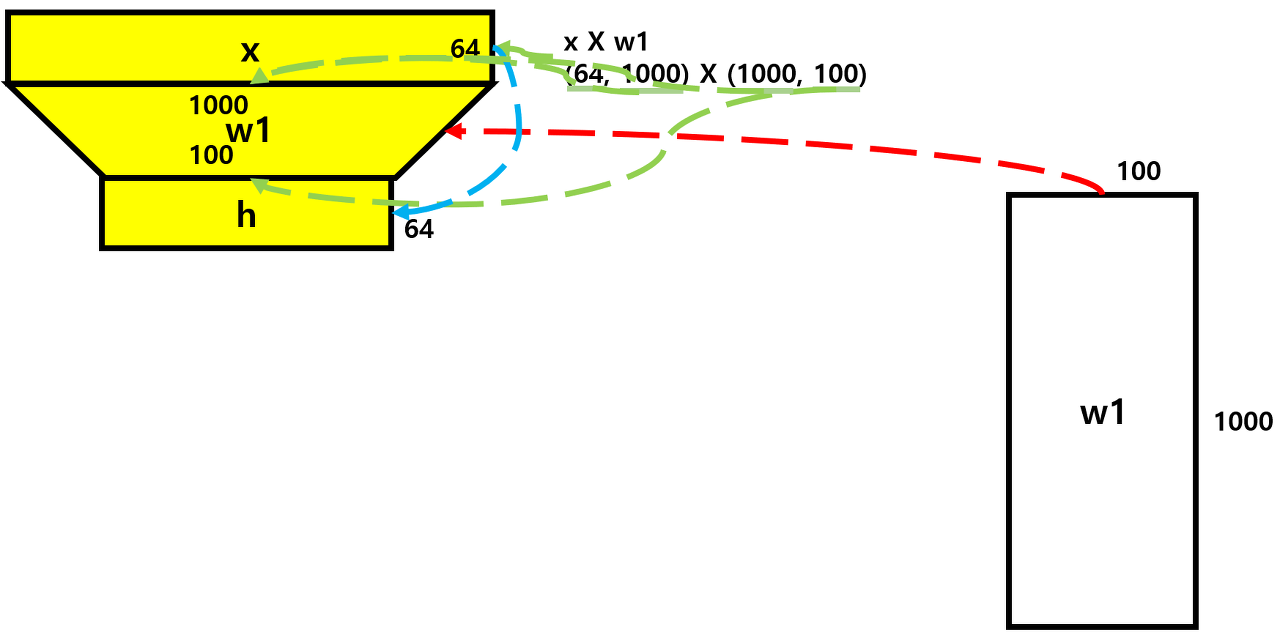

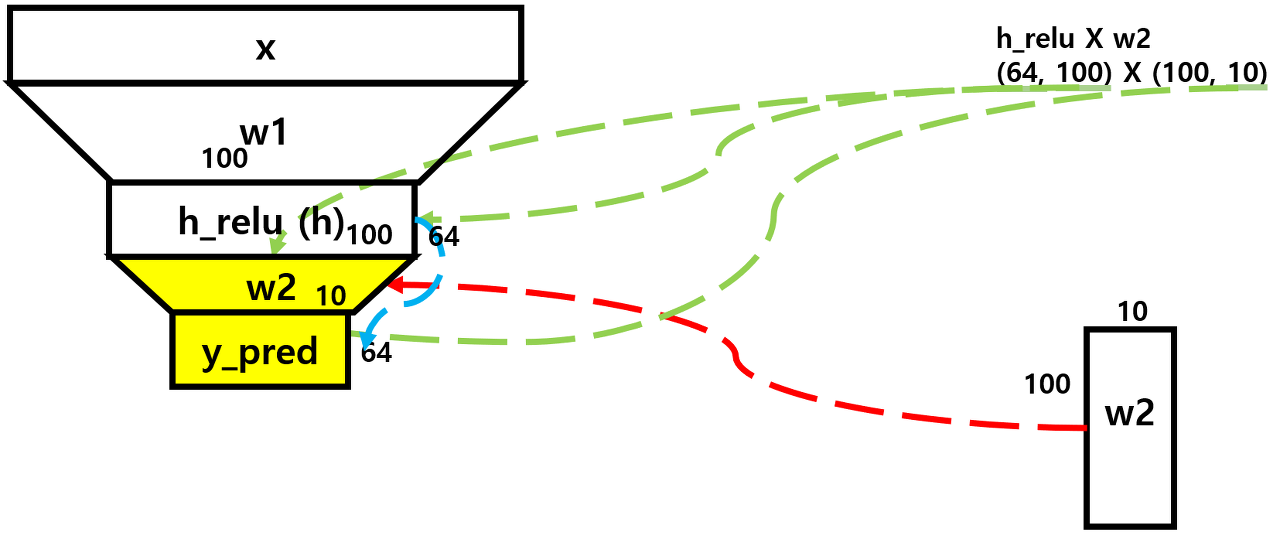
- 지난 시간에 만든 세 줄의 코드를 한 줄로 간소화하였다.
loss function
loss = (y_pred - y).pow(2).sum()
'''지난시간
loss = (y_pred - y).pow(2).sum().item()
'''
- loss function으로 (예측값-실제값)^2의 방식을 취하였다.
- 지난시간에 사용하였던 .item()부분을 삭제하였다
1) item()은 tensor에 저장된 값을 추출하는 의미이다.
loss function 미분 ~ backward
loss.backward()
'''지난시간
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
'''




- loss function의 미분으로 시작해서 각 가중치의 gradient를 역산하는 과정이다.
- backward() 함수에 모든 과정이 포함된다.
weight 갱신
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
'''지난시간
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
'''

- 지난시간과 동일하다.
gradient 초기화
w1.grad.zero_()
w2.grad.zero_()

- w1, w2의 gradient를 초기화 하는 부분이다.
- 초기화 하지 않을시 gradient가 누적이되어 잘못된 값이 나오게 된다.
속도비교

- autograd를 사용했을때 기존(수동으로 backward 구현)보다 빠르게 연산된다는 것을 알 수 있다.
'인공지능 & 머신러닝 > PYTORCH' 카테고리의 다른 글
| [PYTORCH] 06_pytorch with examples (nn module) (0) | 2019.06.16 |
|---|---|
| [PYTORCH] 05_pytorch with examples (TensorFlow) (0) | 2019.06.16 |
| [PYTORCH] 04_pytorch with examples (autograd 재정의) (0) | 2019.06.10 |
| [PYTORCH] 02_pytorch with examples (tensor) (0) | 2019.05.29 |
| [PYTORCH] 01_pytorch with examples (numpy) (0) | 2019.05.26 |



