인공지능 & 머신러닝/kaggle
[kaggle] Intro to Deep Learning 수료과정
pbj0812
2021. 4. 21. 08:17
0. 목차 및 내용
1) A Single Neuron
- 뉴런 설명
- keras.Sequential 을 이용한 인풋 설계까지
2) Deep Neural Networks
- 활성화 함수, ReLU, 레이어 쌓기
3) Stochastic Gradient Descent
- 로스 함수, 옵티마이저, 학습률, 배치 사이즈
4) Overfitting and Underfitting
- 언더피팅, 오버피팅,
- 적정한 구간을 찾기 위한 Early Stopping

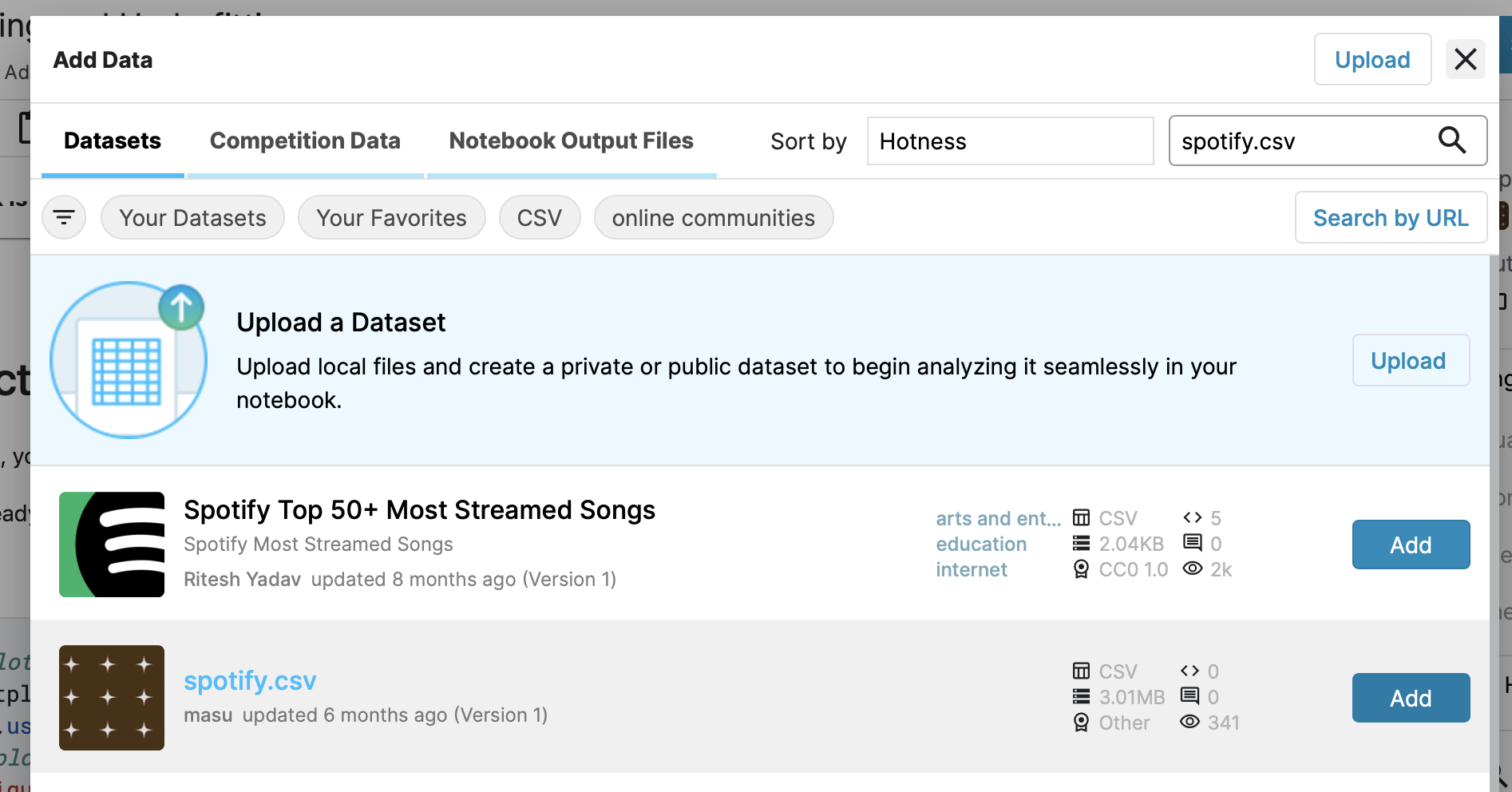
- 문제 도중에 csv 가 없다는 일이 발생하였는데 아래 그림과 같이 우상단의 add data 를 누르고 spotify.csv 를 받은 이후 위치 설정하면 해결
5) Dropout and Batch Normalization
- 드롭아웃
- Batch Normalization
6) Binary Classification
- binary classification
1. 참고를 위한 마지막 코드 중 일부(모델 구성)
from tensorflow import keras
from tensorflow.keras import layers
# 모델 구성
model = keras.Sequential([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(0.3),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(0.3),
layers.Dense(1, activation='sigmoid'),
])
# 컴파일
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
# 얼리스토핑
early_stopping = keras.callbacks.EarlyStopping(
patience=5,
min_delta=0.001,
restore_best_weights=True,
)
# 학습
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=200,
callbacks=[early_stopping],
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot(title="Cross-entropy")
history_df.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot(title="Accuracy")3. 수료증
